PIGEON: Predicting Image Geolocations
Planet-scale image geolocalization remains a challenging problem due to the diversity of images originating from anywhere in the world. Although approaches based on vision transformers have made significant progress in geolocalization accuracy, success in prior literature is constrained to narrow distributions of images of landmarks, and performance has not generalized to unseen places. We present a new geolocalization system that combines semantic geocell creation, multi-task contrastive pretraining, and a novel loss function. Additionally, our work is the first to perform retrieval over location clusters for guess refinements. We train two models for evaluations on street-level data and general-purpose image geolocalization; the first model, PIGEON, is trained on data from the game of Geoguessr and is capable of placing over 40% of its guesses within 25 kilometers of the target location globally. We also develop a bot and deploy PIGEON in a blind experiment against humans, ranking in the top 0.01% of players. We further challenge one of the world's foremost professional Geoguessr players to a series of six matches with millions of viewers, winning all six games. Our second model, PIGEOTTO, differs in that it is trained on a dataset of images from Flickr and Wikipedia, achieving state-of-the-art results on a wide range of image geolocalization benchmarks, outperforming the previous SOTA by up to 7.7 percentage points on the city accuracy level and up to 38.8 percentage points on the country level. Our findings suggest that PIGEOTTO is the first image geolocalization model that effectively generalizes to unseen places and that our approach can pave the way for highly accurate, planet-scale image geolocalization systems. Our code is available on GitHub.
CVPRのポスターでだいたい理解していたのだけれど、再現実験できるほどの詳細は語られていなかったので論文を精読しつつコードも読んだ。たぶんすぐ忘れるので情報をまとめる。
概要
画像からGeoguessrのように地理的位置特定(image geolocalization)するシステムの提案をする論文。従来アプローチはランドマークなどの限られた画像に対してのみ精度が向上するようなピーキーさがあったけど、未知の場所に対しても対応できる能力の獲得を狙った提案になっている。メインの貢献はsemantic geocellの作成(データは非公開)とgeocell間の距離を考慮した損失関数の提案。実証実験としてGeoguessrの有名プロプレイヤーRainboltと対戦して6戦全勝している。
マルチタスクや階層的な推論はあまり重要性ではなさそうなのでメモしない。
Geocellのデザイン
クラス分類として解くため、地球表面をクラスラベルに分割する必要がある。この分割された表面をgeocellと呼ぶ。理想的には、それぞれのgeocellは地理的エリアの区別可能な特徴を捉えていることが望ましい。政治的・行政的な境界線は、国や地域固有の情報(道路標識や信号機など)を捉えるだけでなく、川の流れであったり山脈などの自然の境界線に沿っていることが多いため、この目的に適している。
PIGEONはGDAM (グローバル行政区画データベース) から得た3つのレベルの行政境界(country、admin1、admin2)を利用してsemantic geocellをデザインしている。最も細かいレベル(admin2)に訓練事例が存在しないことがあり得る。そのためadmin2から開始して、各ジオセルが少なくとも最小の訓練サンプルを含むように、隣接するadmin2 levelのポリゴンをマージしていく。既存研究の手法と異なり、admin1 levelの境界によって与えられている階層を維持するように制約付きでマージを試みる。
これは日本に置き換えて考えるとadmin1は都道府県レベルの行政境界、admin2は市区町村レベルの行政境界。admin2は10 km^2の台東区や905 km^2の広島市など様々な広さの違いがある。マージの制約は単一のgeocellに複数の都道府県をまたぐことはないことを意味している。
クラスタリングとボロノイ分割
いくつかのadmin2領域は十分にきめ細かくないという問題がある。特に大規模な訓練データセットの場合に問題となる。各ジオセルには最小の訓練サンプルを含むように分割したい一方で、都市部のadmin 2領域には大量の訓練事例が割り当てられる可能性がある。そのためGDAMのadmin2領域を更に有意義に分割する必要がある。
これは緯度経度を元にOPTICSクラスタリングを使ってクラスタを抽出することで分割する。クラスタリングの結果のうち、未割り当てのoutlierは最も近いクラスタに割り当てる。最後にVoronoi tessellationによって全ての抽出したクラスタに対して切れ目のない領域を定義してgeocellとする。
距離に基づくラベルのスムージング
geocellの粒度を細かくすると細かい予測ができるようになる一方で、cardinalityが高くなるので分類問題が難しくなる。正解と距離の近いgeocellであれば、だいたい正解であるとモデルに教えることで改善が見込める。この距離としてhaversine distance(これは球面上の2点間の最短距離)を使って損失関数を設計する。
以下のように距離に基づいてラベルを次のようにスムージングする。
はgeocell のcentroid、はgiven sampleのtrue geocellのcentroid、はgiven sampleの真の座標。結果として、geocellを厳密に正解しなくても予測geocellのcentroidがtargetの座標と近ければある程度正解であるとみなす。expの中に2つのhaversine distanceが含まれている点に注意する。正しいジオセルへの距離と真の位置との距離の2つに基づいてラベルが減衰するようになっている。最終的な損失関数は以下のようになる。
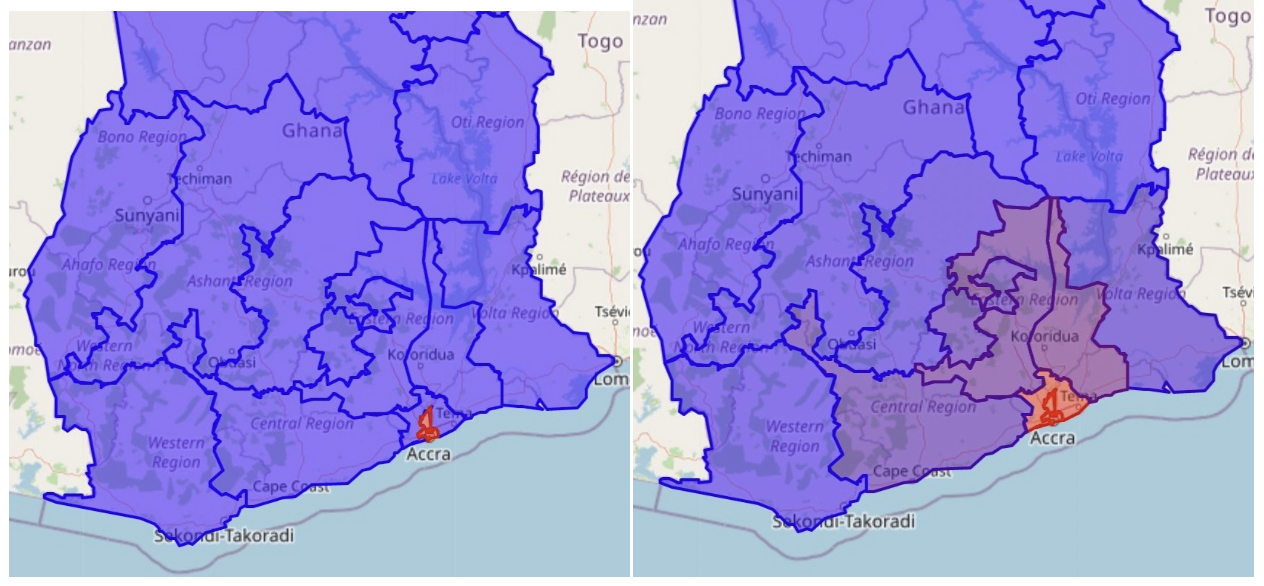
スムージングされたラベルの比較は以下の通り。周辺のgeocellにもスムーズにラベルが割り当てられている。
Geographic synthetic captions
訓練データとして画像のキャプション情報を生成して用いている。キャプションは具体的に以下のようなものをテンプレートに従って生成している。
- Location: “A photo I took in the region of Gauteng in South Africa.”
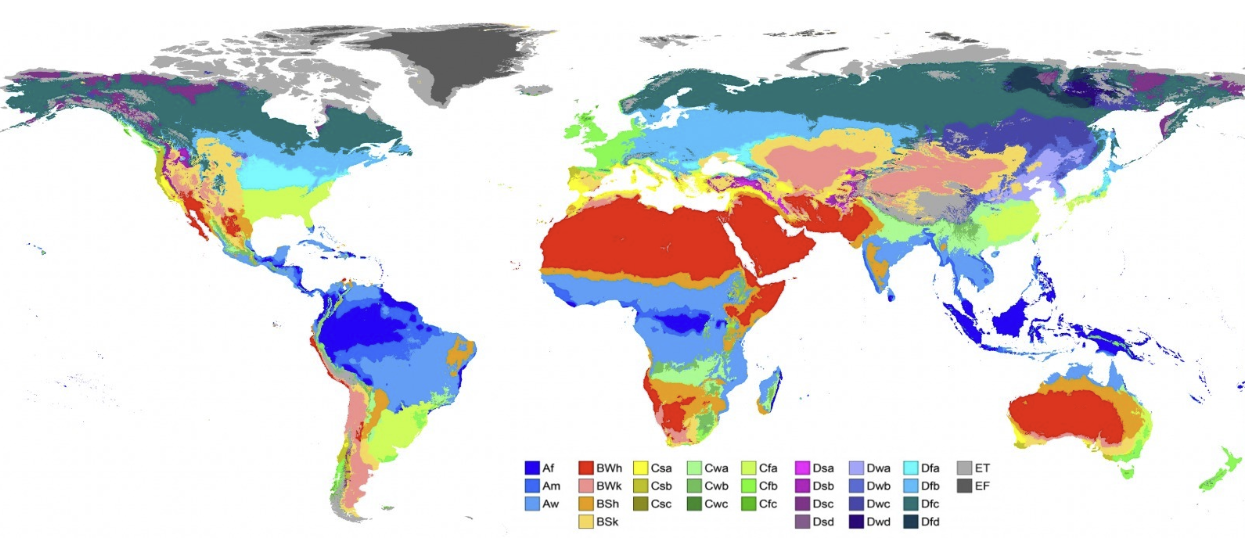
- Climate: “This location has a temperate oceanic climate.”
- Compass direction: “This photo is facing north.”
- Season (month): “This photo was taken in December.”
- Traffic: “In this location, people drive on the left side of the road.”
これらは様々な地理データを緯度経度から辞書引きしている。たとえば気候についてはケッペンの気候区分を参照して生成している。Temperate oceanic climateは西岸海洋性気候(Cfb)。
地理情報などのキャプションとContrastive CLIP Pretrainingによってモデルを訓練することで、結果として植生や交通事情などの地域性の習得を見込む。またモデルの目標変数にはGeoCLIP(2023)のように緯度経度を直接用いるのではなく、geocellという地球表面を分割したクラスラベルを用いている点が異なる。
作成したデータセットごとに2つのモデルを作成している。一つはGeoguessr(Google Streetview)に特化したPIGEON。Google Streetviewなので、路上からの風景がメインで特定の地域(中国の大部分)が含まれていないなどのバイアスがありそう。二つ目はFlickr(YFCC)やWikipedia(Google Landmark Dataset V2)の画像データで訓練したもの。ランドマークの画像が中心なので、こちらもやはりバイアスがありそうである。
疑問点:Geocellの元となる境界データはどれか
論文で言及されている境界データは二種類ある。
-
(1) The William & Mary Geospatial Evaluation and Observation Labからリリースされている”political boundaries of administrative areas”
Appendix C を読む限りだとgeocellの生成過程においては(1)が使われていると書かれている。しかしFigure 5ではGADMから得た”political boundaries”を元にgeocellを生成すると記述している。本文でも文脈から読むとGADMを使っていると読むことができる。どっち?!
ソースコードを読むと境界データはそれぞれ以下のファイル名で保存されている。
- geoBoundariesCGAZ_ADM2.geojson
- gadm_410-levels.gpkg
geocellの生成コードでは以下のファイルをロードして初期値としている。
- data/geocells/admin_2.geojson
どっち?!どのように admin_2.geojson を生成しているかのコードは含まれていない。たぶんだけどGADMのgpkgファイルに複数の階層の境界データが含まれているので、gadm_410-levels.gpkg を階層ごとに分離して admin_2.geojson を作成しているのではないかと想像する(要質問)
所感
モデルは倫理的な観点から非公開。生成したgeocellも非公開。コードは公開されているが、いきなり未知のファイル名が入力になっているなど厳しいものがある。上述したように、論文の本文も特にデータの扱いについて矛盾があるように見える。せめてgeocellは公開してほしかった or ちゃんと再現できるコードを公開してほしかった。
再現性に厳しいところがありつつ、 synthetic geo-captionsとのcontrastive CLIP pretrainingによって地域特有の外観をうまく学習してくれていそうなのが良い。label smoothingもgeocellの距離関係をうまく使っている。温度パラメータごとの実験をして、smoothingの効果を検証したさがある。
ここにはまとめていないが推論方法のlocation cluster retrievalは改善の余地がありそう。計算効率は良いが、最終的に単一のクラスタから緯度経度を推定している点はtop-kを活用できないかと思う。ほかlocation cluster に対する表現ベクトルをすべての事例の平均にするところも改善余地がありそう。

