LLM のファインチューニングにおいて入力トークン列の packing と Attention 計算の効率化は、長いトークン列を扱う際に特に重要です。この記事では、長さの異なる入力トークン列を packing によってコンパクトにまとめて、追加の変換処理を行うことなく、Flash Attention のオリジナルの論文実装である flash-attn パッケージにある varlen (variable-length) interface である flash_attn_varlen_func 関数にシームレスにつなげて Attention 計算する実装を紹介します。
本記事の要点は以下のとおりです:
-
Packing と Flash Attention は長いトークン列を扱う上で重要
-
Packing による Micro-batch のサイズが均等になるように Collator を用意することで効率化
Padding vs Packing
LLM の訓練時において、ミニバッチ内の入力トークン列の padding は、長さが異なる複数のトークン列をまとめて扱うための一般的な手法です。しかし、padding のために用いられる padding token は、モデルの学習においては本質的な情報を持たないため、計算リソースの浪費や非効率化につながる場合があります。ミニバッチ内において入力トークン列の長さのばらつきが大きい場合、入力データの大部分が padding token によって埋められてしまい、メモリ空間の効率が悪いです。
packing (example packing, sequence packing とも言われる) は、複数のトークン列を連結して一つの長いトークン列として扱うことで、メモリ空間を効率化します。packing されたトークン列の境界を正しく扱えば、下図のように packing 前の example ごとに Attention を計算することで、Attention 計算においても計算効率の向上が期待できます。
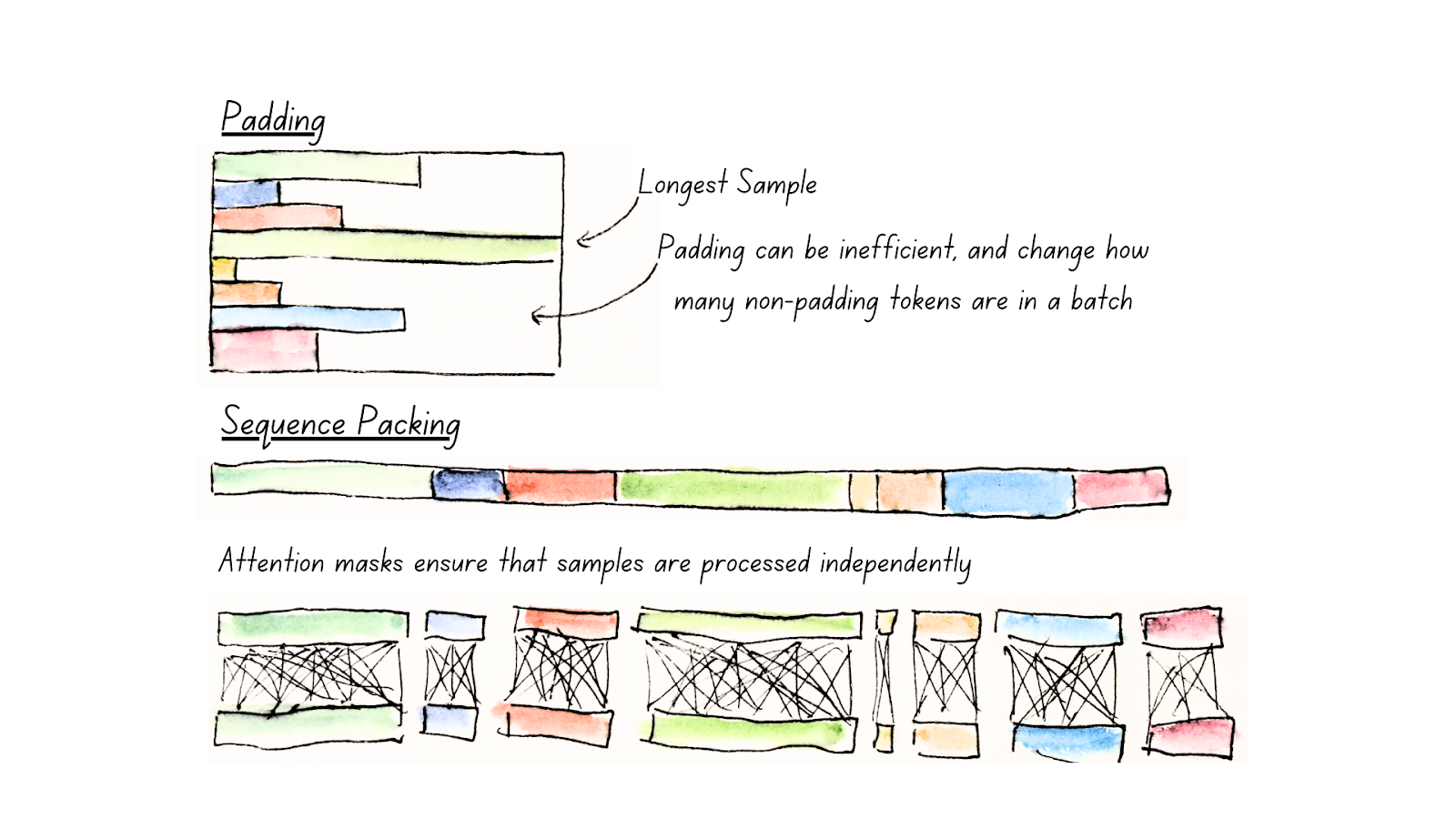 (図: padding と packing の比較。図は ModernBERT のブログ記事
Finally, a Replacement for BERT より引用)
(図: padding と packing の比較。図は ModernBERT のブログ記事
Finally, a Replacement for BERT より引用)
Flash Attention と variable-length interface
長いトークン長を扱う上では Attention の計算にも注意が必要です。Standard な Attention 計算では、入力系列に対して2次関数のオーダーのメモリを必要とするため、トークン長を大きくすると OOM (Out of Memory) エラーに悩まされることになります。Flash Attention は、大幅なメモリ節約(2次関数ではなく線形)と実行時間の高速化を、近似なしで実現します(すごい)。
Flash Attention ではGPUメモリのレベル間の読み書きの IO に注目して、HBM へのIOアクセスを減らすことで高速化を実現しています。GPU には転送速度の異なる SRAM と HBM があり、SRAM は HBM に比べて容量が小さいものの高速であるという特徴があります。
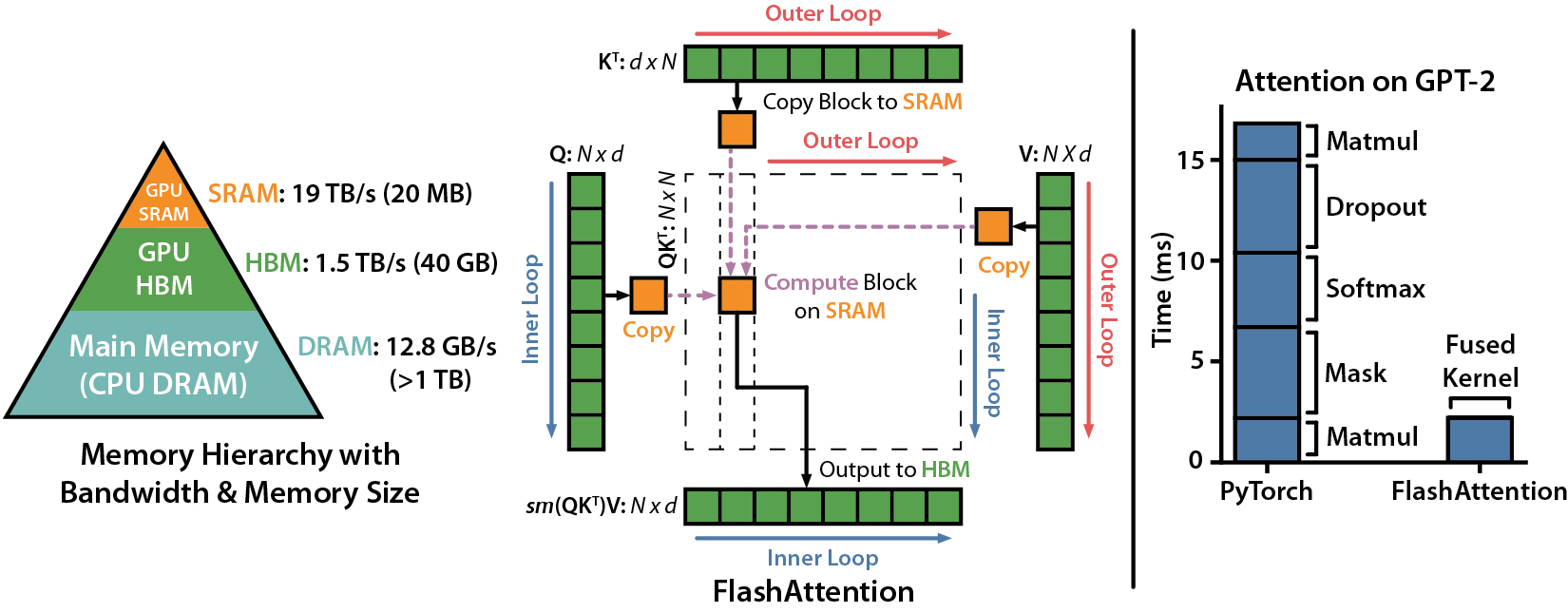 (図: SRAM と HBM の性質の違いを利用して大幅なメモリの節約と実行時間の高速化を実現している。Flash Attention の論文より引用。)
(図: SRAM と HBM の性質の違いを利用して大幅なメモリの節約と実行時間の高速化を実現している。Flash Attention の論文より引用。)
余談ですが、以下の YouTube 動画は Standard な Attention 計算と Flash Attention の step-by-step の操作を可視化したオススメ動画です。HBM へのアクセスを減らすために SRAM 上の操作を工夫している点がわかりやすく可視化されています(アルゴリズムがわかりやすいとは言っていない)。
variable-length (varlen) interface
Flash Attention のオリジナル実装である flash-attn パッケージには variable-length (varlen) interface として flash_attn_varlen_func 関数が用意されており、cu_seqlens という引数を通じて、packing されたトークン列における各 example の境界位置を渡すことで、example ごとに attention を計算するためのインターフェースが用意されています。
varlen は attention の complexity を から にすることができ、計算コストを抑えることができます。ここで はパッキングされる前の i 番目のトークン列の長さを表します。 メモリのオーダーは linear ですが計算のオーダーは依然として quadratic です。下右図は time complexity が linear に見えますが、これは packing 前が 1k の sequence であるという前提における結果です。 が固定されているため、length に対して liner な time cost の増加関数が得られています。
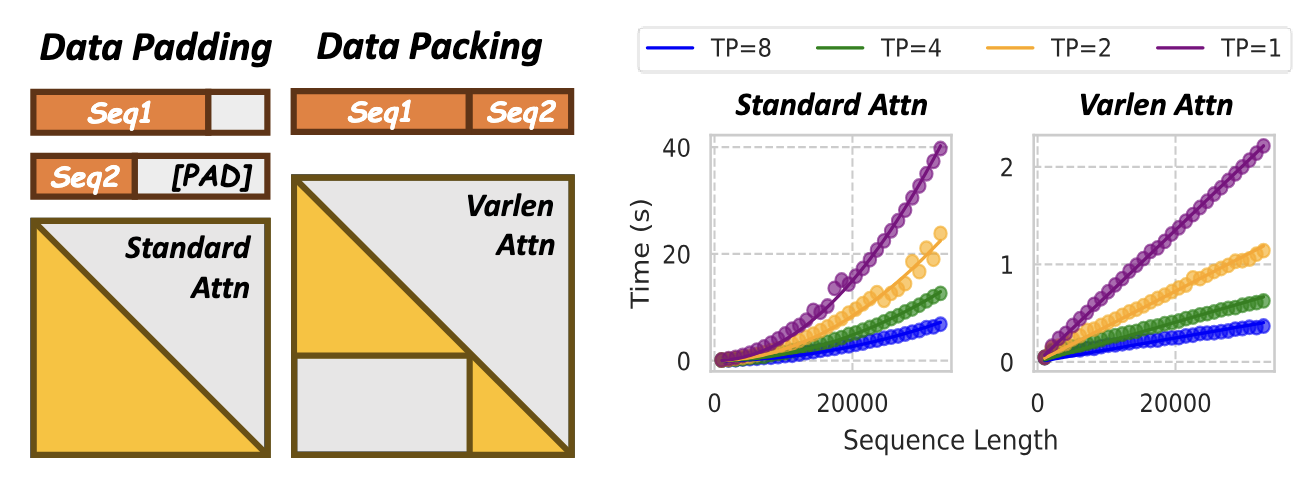 (図: varlen interface によって sequence ごとに attention 計算されて length に増加に対してもスケールすることを端的に表している図。図の面積は quadratic だけど、実際の flash attention では quadratic なメモリ空間を必要としない。Hydraulis の論文より図を引用。)
(図: varlen interface によって sequence ごとに attention 計算されて length に増加に対してもスケールすることを端的に表している図。図の面積は quadratic だけど、実際の flash attention では quadratic なメモリ空間を必要としない。Hydraulis の論文より図を引用。)
以上で packing と Flash Attention の varlen interface について簡単な説明をしました。実際に packing したデータをモデルに渡すためには、DataCollator などで複数の examples の系列を packing してモデルに渡すための変換が必要です。以降では、この記事の本題である packing のための DataCollator について説明します。
HF の Flattening
Hugging Face の transformers ライブラリには、Flash Attention 対応にあわせて、packing と Flash Attention による Attention 計算をシームレスに連携させるための DataCollator として DataCollatorWithFlattening が実装されています。この DataCollator を利用することで、余計なデータ変換処理を記述することなく効率的な学習を行うことができます。以下のレポートでは、学習のスループットを2倍に改善したと報告しています。
しかしながら、DataCollatorWithFlattening は、ドキュメントや具体的な使用例がほとんど見当たりません。実装コードを調べたところ、input_ids と labels の扱いから、Causal Language Model (CLM) 以外のタスク、例えば SequenceClassification タスクに Fine-tuning して使用したい場合などは、現時点 (v4.48.3) では想定されていないように見受けられます。
そのことは一旦置いておいて、packing の例を見るために DataCollatorWithFlattening の基本的な使用例と入出力を以下に示します。この DataCollator は、tokenizer で定義されている padding token を必要としないため、DataCollatorWithPadding のように tokenizer を渡す必要はありません。
from transformers import DataCollatorWithFlattening
collator = DataCollatorWithFlattening()
input_data = [
{"input_ids": [1, 2, 1]},
{"input_ids": [3, 4, 5, 4, 5, 6]},
]
data = collator(input_data)
print(data)上記のコードを実行すると、以下のような出力が得られます。
{
'input_ids': tensor([[1, 2, 1, 3, 4, 5, 4, 5, 6]]),
'labels': tensor([[-100, 2, 1, -100, 4, 5, 4, 5, 6]]),
'position_ids': tensor([[0, 1, 2, 0, 1, 2, 3, 4, 5]])
}ミニバッチ内の全てのトークンが単一のトークン列に連結され、shape が (1, total_tokens) のテンソルが生成されます。labels テンソルにおいては、デフォルトで各トークン列の先頭が区切り ID (デフォルト値は -100) で埋められています。
このデータを、例えば Gemma2 などの AutoModelForCausalLM で定義されるモデルに入力すると、position_ids に基づいて position embeddings が計算され、decoder layer に position embeddings と hidden states が渡されて Attention 計算が行われます。Attention 計算においては、attn_implementation パラメータに “flash_attention_2” を指定することで、最終的に flash-attn 実装の flash_attn_varlen_func 関数が呼び出されます。
model_name = "google/gemma-2-2b-it"
model = AutoModelForCausalLM.from_pretrained(
model_name
attn_implementation="flash_attention_2",
)
print(model(**data))mini-batch のサイズの不均衡さ
HF の DataCollatorWithFlattening は、これ単体ではいくつかの課題が残ります。その一つとして、mini-batch ごとのバッチサイズ(連結された単一のリストの長さ)が不均衡であるという課題があります。これは DataCollatorWithFlattening が DataLoader から与えられる入力系列を系列長に関係なく系列の件数ベースで Collator に渡していることに起因します。
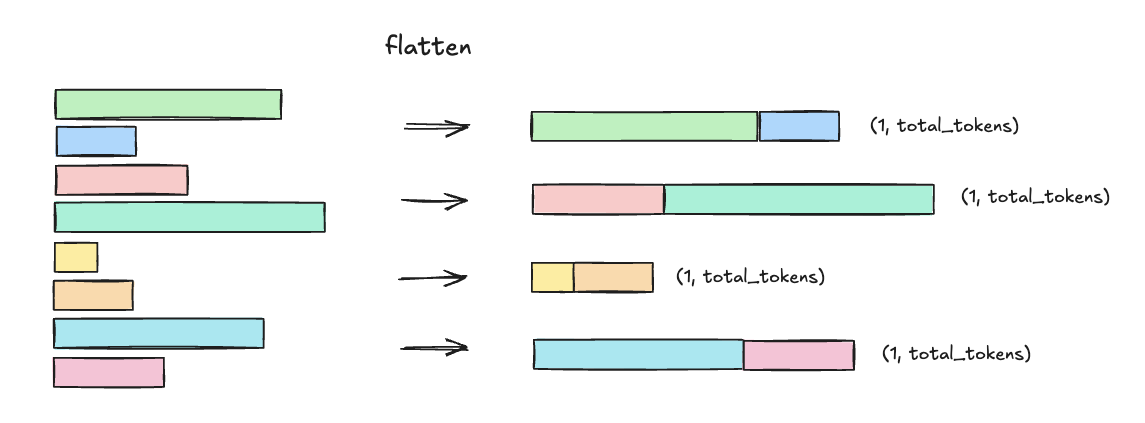 (図) DataLoader で
(図) DataLoader で batch_size=2 とした上で Collator にデータを渡した場合の例。
たとえば OOM を避けるためにフラット化された系列のサイズが一定のサイズよりも小さく保ちたいといった調整が難しいく、柔軟性に欠けます。理想としては、OOM を回避できる範囲で可能な限り長い系列を扱うことができ、mini-batch ごとのサイズである (1, total_tokens) もなるべく均衡になるように packing して欲しいところです。
mini-batch のサイズが変動しやすいという課題は、分散並列学習を行う際にも影響を及ぼします。分散並列学習を行う際には、各GPUに均等にデータを分配して GPU の idle 状態が発生しないよう気を配る必要があります。この mini-batch のサイズのばらつきについての要望は Issue に上がっています。
次に紹介する tascj 実装の ShardedMaxTokensCollator はこの課題を解決する一つの手段になります。
ShardedMaxTokens Collator
本題の ShardedMaxTokensCollator です。HF の DataCollatorWithFlattening が CLM 以外の SequenceClassification などに直接使用できない点は前述したとおりです。できなければ自分たちで実装する必要があります。Kaggle で開催された LMSYS - Chatbot Arena Human Preference Predictions コンペティション における、tascj らのソリューションがこれを実装していたので紹介します。
ShardedMaxTokensCollator は、シャードごとに packing した後の入力系列の長さが均衡するようにデータを変換して micro-batch を作る Collator となっています。均衡したサイズに packing した micro-batch を作ることで、ほかの GPU による計算が終わるまで待つといったことが少なくなり、複数 GPU 使用時の利用効率の向上が期待できます。
実装では、均衡な micro-batch を作るために、DataLoader から複数イテレーション分のデータをまとめて Collator に渡します。そして短い系列から順番に max_tokens に収まるように packing することで、おおまかに均衡になるよう micro-batch を作成しています。ソートを使ったナイーブな実装ではありますが、これで十分に均衡な micro-batch が得られます。
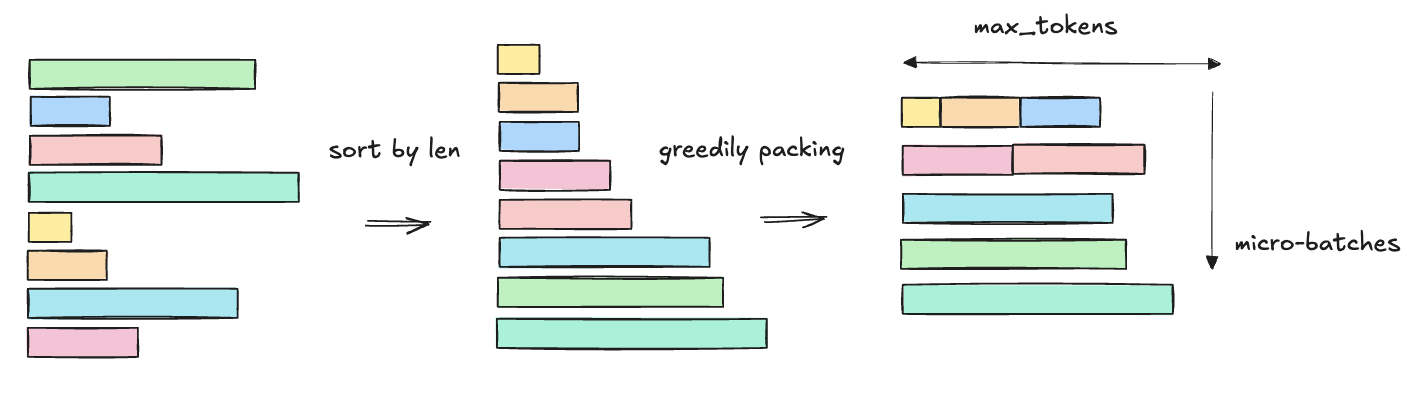 (図: 長さの異なる系列を長さでソートして、短い系列から順番に取り出すことで、ある程度均衡したマイクロバッチを構成している。)
(図: 長さの異なる系列を長さでソートして、短い系列から順番に取り出すことで、ある程度均衡したマイクロバッチを構成している。)
ShardedMaxTokensCollator では packing する examples をまとめるまでの実装が記述されており、複数の examples を連結して (1, total_tokens) に変形する部分は次に紹介する VarlenCollator で行われます。これは self.base_collator でインスタンス化されています。
sample_index_matrix = torch.arange(len(samples)).reshape(-1, self.world_size)
size_matrix = torch.tensor(
[sample["input_ids"].size(0) for sample in samples]
).reshape(-1, self.world_size)
micro_batch_segments = []
# (start, end) that (size_matrix[start:end].sum(0) <= self.max_tokens).all()
start = 0
for end in range(size_matrix.size(0)):
# look ahead
if (
size_matrix[start : end + 1].sum(0) > self.max_tokens
).any() and end > start:
micro_batch_segments.append((start, end))
start = end
if start < size_matrix.size(0):
micro_batch_segments.append((start, size_matrix.size(0)))
micro_batches = []
for start, end in micro_batch_segments:
micro_batch_samples = [
samples[i] for i in sample_index_matrix[start:end, self.rank]
]
micro_batches.extend(self.base_collator(micro_batch_samples))
return micro_batchesVarlenCollator
ShardedMaxTokensCollator で使われている self.base_collator は、入力系列である input_ids から、packing された形式を作成し、position embedding に用いる position_ids と Flash Attention の varlen interface にわたす cu_seqlens を作成する Collator となっています。これは素直な実装なので、特に特筆することはない。
class VarlenCollator:
def __call__(self, samples):
seq_lens = []
cu_seqlens = [0]
end = 0
input_idss = []
position_idss = []
for sample in samples:
seq_len = sample["input_ids"].size(0)
seq_lens.append(seq_len)
end += seq_len
cu_seqlens.append(end)
input_idss.append(sample["input_ids"])
position_idss.append(torch.arange(seq_len))
input_ids = torch.cat(input_idss, dim=0)
position_ids = torch.cat(position_idss, dim=0)
(snip)Gemma2 モデルのインターフェースの変更
tascj による LMSYS コンペのソリューション実装は transformers の v4.43.3 (Jul 27, 2024) の Gemma2 モデルをベースに高速化のための修正や Flash Attention の varlen interface へのシームレスな接続のための forward() の仕様変更を行っています。
v4.43.3 では Attention の forward() 内で _upad_input() 関数によって examples 間の境界を取り出したり内部での帳尻合わせがありました。tascj の実装では、前述した DataCollator で cu_seqlens を作成して forward() に直接渡すように変更しています。
class Gemma2Attention(nn.Module):
(snip)
def forward(
self,
hidden_states,
cu_seqlens,
rotary_emb,
is_last_decoder_layer=False,
):ここで渡した cu_seqlens を flash-attn の flash_attn_varlen_func() に渡しています。
コードを比較すると、他にも transformer engine 実装の RMSNorm への置き換えや FusedRoPEFunc の使用など、高速化のための工夫が多く見られます。
最新の transformers 実装と MultiPackSampler
幸いなことに、現在最新の v4.48.3 (Feb 2, 2025) の transformers パッケージの Gemma2Model クラスや Gemma2Attention クラスを見ると packing に対応したインターフェースを forward() に備えており、そこから varlen interface へシームレスに接続しています。
そのため Gemma2Model をそのまま使い Gemma2ForSequenceClassification に替わるものだけを用意すれば ShardedMaxTokensCollator を使いながら Sequence Classification としてファインチューニングすることがより簡単にできそうです(まだ試していない)。以下は Gemma2Model の forward() メソッドのシグネチャです。
@add_start_docstrings_to_model_forward(GEMMA2_INPUTS_DOCSTRING)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[HybridCache] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
cache_position: Optional[torch.LongTensor] = None,
last_cache_position: Optional[int] = None,
**flash_attn_kwargs: Unpack[FlashAttentionKwargs],
) -> Union[Tuple, BaseModelOutputWithPast]:このうち flash_attn_kwargs キーワード引数は次のようになります。
class FlashAttentionKwargs(TypedDict, total=False):
"""
Keyword arguments for Flash Attention with Compile.
Attributes:
cu_seq_lens_q (`torch.LongTensor`, *optional*)
Gets cumlative sequence length for query state.
cu_seq_lens_k (`torch.LongTensor`, *optional*)
Gets cumlative sequence length for key state.
max_length_q (`int`, *optional*):
Maximum sequence length for query state.
max_length_k (`int`, *optional*):
Maximum sequence length for key state.
"""
cu_seq_lens_q: Optional[torch.LongTensor]
cu_seq_lens_k: Optional[torch.LongTensor]
max_length_q: Optional[int]
max_length_k: Optional[int]input_ids を (1, total_tokens) の packing した形式で渡し、position_ids と cu_seqlens と max_length を Gemma2Model にわたすようにモデルを定義すると良さそうです。
また、本記事では Collator で packing を行う実装について紹介しました。Sampler で packing を行う実装もあり、むしろこっちのほうが一般的かもしれません。
MultiPackSampler は以下のように使います。すべてのトークンの長さを事前に用意して Sampler に渡す仕様になっています。ShardedMaxTokensCollator は一定サイズの先読みであったのに対して、最適化するサンプルがより大域的な最適になっていそうです。
batch_max_len = 16 * 2048 # batch size * max context length
lengths = np.array([len(tokens) for tokens in data])
sampler = MultipackDistributedBatchSampler(
batch_max_length=batch_max_len,
lengths=lengths,
seed=0
)
dataloader = DataLoader(data, batch_sampler=sampler)あくまでも Sampler なので、VarlenCollator のような Data Collator を用意する必要があります。 大域的な最適を目指してサンプリングすることで、ランダムネスへの影響であったり、精度や速度にどう影響するのか気になるところです。 誰か実験して結果を教えて下さい。あるいは実験するので A100-80G なり Hopper な GPU リソースをたくさん貸してくださいお願いします何でもします。
まとめ
-
ShardedMaxTokensCollator で packing された micro-batch を作成することで、mini-batch のサイズの不均衡さを解消し、複数 GPU 使用時の利用効率を向上させることができる。
-
最新の transformers パッケージの Gemma2 モデルは packing のためのインターフェースを持ち、varlen interface へのシームレスな接続が可能。
-
MultiPackSampler は Sampler で packing を行う実装で、ShardedMaxTokensCollator よりもより大域的な最適化が期待できる。
所感
Kaggle コンペではソフトウェアエンジニアリングも強みになるという良い事例として、私自身も大変勉強になったので紹介するためにこの記事を書きました。昨今ではライブラリの Trainer クラスに全任せすることも多くなってきましたが、データ特性にあわせて少しでも特殊なことをしようと考えると、実装を読んだりカスタマイズしたり自分でコードを書かなくてはいけないという機会もまだ多く残っていると思います。
tascj によるモデル実装は他にも T4x2 という VRAM 14 GB x2 の推論環境にあわせてモデルの前半 Layer と後半 Layer をそれぞれの GPU の VRAM に乗せて並列で推論させる工夫であったりと、エンジニアリング面の面白い工夫が多くて好きです。flash-attn は Ampere, Hopper などの新しめの arch しかサポートしていません。Kaggle の T4 で動かすためには、代替する実装が必要で… などなど。もっと多くの人に読んで欲しい。

