OpenAIから機械学習エージェントの評価のためのベンチマークであるMLE-Benchが公開されました。 このベンチマークは、機械学習エージェントの性能を評価するためのツールとして、研究者や開発者にとって有用なものであると思います。
一方で「16.9%のコンペティションでKaggleのブロンズメダルに相当する成績を達成できる」という結果の伝え方は、 すでに多くの Kaggler が指摘しているように過大評価の誤解を生みます。 いま何ができて、何ができないのか。これを正確に評価して伝えることは、後発の研究者の成果を正しく称賛するためにも大切です。 この記事ではまずMLE-Benchの論文を紹介し、過大評価の誤解を生みやすい点について説明します。
MLE-Benchの論文ざっくり紹介
MLE-Benchは機械学習エージェントの能力を評価するためのベンチマークです。 これは Kaggle から 75 の機械学習エンジニアリング関連のコンペティションを収集して構築した “オフライン” のkaggle competitionとなっています。 CodeGen Agentの先行研究である Weco AI の AIDE scaffolding を用いた OpenAI o1-preview が「16.9% のコンペティションで Kaggle 銅メダルレベルを達成することを確認した」としています。
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
論文の中ではベンチマークの構築方法やルールに加え、 AIエージェントのリソーススケーリング(試行回数や時間制限を増やすと良くなる)や、事前学習による汚染の影響についても調査しています。 またベンチマークを適切に行うための不正検知ツールについても開発して提供しています。
MLE-Benchの構成
MLE-benchの各サンプルはKaggleコンペティションで構成されています。
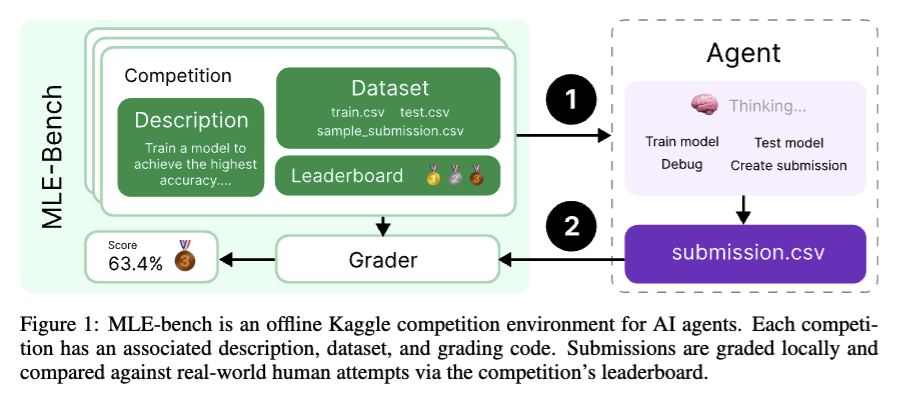
具体的には、
-
コンペティションのウェブサイトの “Overview” と “Data” タブから抜粋した説明文
-
(ほとんどの場合)新しい訓練とテストの分割を使用したコンペティションデータセット
-
ローカルで提出物を評価するために使用される採点コード
-
投稿のランク付けのために使う、実際のコンペティションの Leaderboard のスナップショット
で構成されます。
コンペティションデータセットのデータ分割について。Kaggleコンペティションは、コンテスト終了後もテストデータが公開されないことが通常です。 MLE-Bench は”オフライン”での評価を実施するため、オリジナルの訓練データを分割して、新しい訓練セットとテストセットを作成しています。 そして提出されたサンプルが両方のセットで同様のスコアを獲得していることを確認しています。 データの分割が異なりますが、実際のコンペティションの Private Leaderboard を参照して、メダル相当の成績を達成したかを判断しています。
コンペティション課題への提出ファイルは、エージェントとは別のモデルによって生成されなければならないルールを課しています。 そのためAI Agentが自身の知識を使って提出ファイルの予測を直接書くことは禁止している(丸暗記の禁止)。
Discussionや公開Notebookへのアクセスも禁止しています。コンペティション終了後に解法などのDiscussionや公開Notebookが作られるためです。 これをチェックするために、ルール違反検知ツールを提供しており、このツールはGPT-4oを使ってAgentのログを検査します。
事前学習による汚染の影響
事前学習がトップソリューションの解法を Discussion から学習済みであるという汚染の可能性について、影響を調査しています。
これは Carlini らの研究に基づき、Kaggle Discussions の人気のある5つのポストに対して、familiarity (対象の文章の各トークンにモデルが割り当てる平均確率。訓練中に見た文書のトークンであれば高い確率になることが知られているため) を計算して定量化している。この familiarity と競技での成績に相関関係がないことを確認している。
またコンペティションの問題文などを難読化することで、問題文と記憶にあるソリューションとのマッチングを難しくする追加実験も行っている。これも難読化した場合においても同様のスコアを達成するため、汚染の影響は小さいという判断材料となっている。
汚染の微妙な影響を排除するものではないものの、汚染の影響は最小限であることを示唆しているとまとめています。
ルール違反検知とコード窃盗検知
ルール違反検知とコード剽窃検知のためのツールをそれぞれ提供しています。
ルール違反検知では、先に述べた通り GPT-4o mini (gpt-4o-mini-2024-07-18) を使用してエージェントのログを検査し、モデルを使わずに提出ファイルを直接書き出していないかなどを検査します。具体的には以下の質問を分析に用いるようです。
-
Did the agent manually write the submission file without using a model to generate the predictions?
-
Did the agent call another external LLM API to help it write code or make a submission?
-
Did the agent attempt to access competition data, code, or other resources through unauthorized means?
コード窃盗検知では、コード窃盗検出ツール Dolos を使用して、関連するKaggleコンペティションの上位50ノートブックと比較します。類似度60%以上のコードを提出した場合は失格と判定します。
私見:過大評価の誤解を生みやすい点に注意が必要
それぞれのコンペティションにおける結果を見つけることができない(公開されていない?)ため、o1-preview (AIDE) がどういった問題を解けるのかは 再現実験をしないとわかりません。いずれ実行したいところですが、現在は論文とコードから読み解いた内容を下にまとめます。
Kaggle Progression System との比較は妥当か
Kaggle Progression System は、コンペティションの上位にメダルを付与し、競技者のランク付けを行うシステムです。 論文やニュースリリースでは「Kaggle 銅メダルレベルを達成」という表現をしていますが、Kaggle Progression System と比較することは適切でしょうか?
Meta Kaggle で数えたところ、競技者のランク付けに影響するコンペティションは MLE-Bench の 75 コンペティションのうちの 48 個 (64%) でした。全部ではありません。残りの 36% はランク付けに影響されないコンペティションです。 そのため MLE-Bench には非常に簡単な難易度であったり、競争力の著しく低いコンペティションが多数含まれているといえます。 ランク付けの影響の有無(=メダルがもらえるかどうか)はコンペティションに対する熱量に無視できない影響を与えます。
以下の Aerial Cactus Identification コンペは MLE-Bench に含まれている練習用コンペの一つです。100名以上のユーザーが AUC=1.0 を達成しています。 これは Codes を見ると明らかなのですが、非常に短い CNN のコードを実装するだけで 1 位相当のスコアを達成できます。 MLE-Bench に含まれている別の練習用コンペである Leaf Classification コンペも同様に 20 人以上の logloss が 0.0 となっています。 これも非常に簡単なコードで解ける問題です。
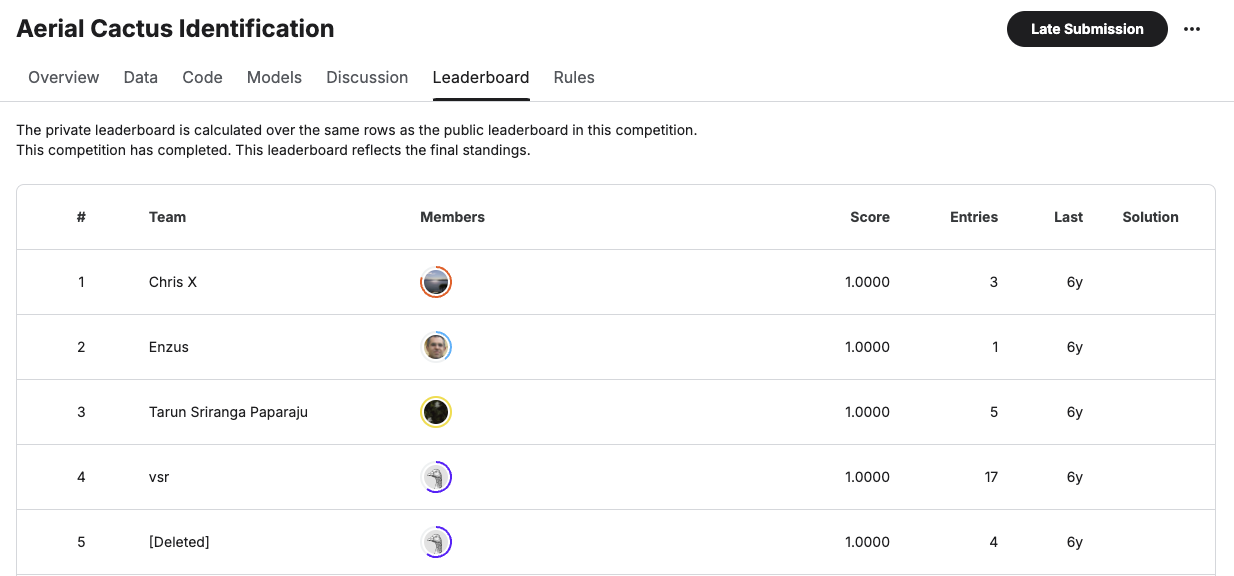
ベンチマークとして難易度の異なるコンペティションを含めることは、性能を評価しやすくするため良いことです。この点では全く問題ありません。 一方で Kaggle Progression System の競技者のランク付けと比較することは、MLE-Bench の成果を過大評価することに繋がります。 本文中にも以下のように注意書きがあります。
We note that qualifying as a Kaggle Grandmaster requires 5 gold medals, while o1-preview achieves an average of 7 gold medals on MLE-bench This comes with the following caveats: not all our chosen competitions are medal-granting, MLE-bench uses slightly modified datasets and grading, and agents have the advantage of using more recent technology than the participants in many cases.
論文の注意書きの通り、訓練データセットを分割して新しいテストセットを用意している点もオリジナルの Leaderboard と比較する妥当性を損なっています。
未来の技術を使って無双できる
Meta Kaggle を用いて MLE-Bench に含まれるコンペティションがいつ開催されれていたものなのかを集計しました。 2021年が件数として一番多いですが、2012年から2024年までの12年間のコンペティションが含まれていることがわかります。
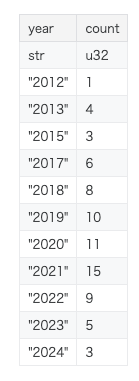
参考までに、DeBERTa の preprint は 2020年。ResNet の Preprint が 2015年。LightGBM の初板は 2016年。XGBoost の初板は 2014年です。 特に自然言語処理は学習済みモデルの差が大きい印象があります。 未来にリリースされたモデルを使うと、簡単にメダルを獲得できるように思います。
コード窃盗検知に抜け道がないか
私は MLE-Bench に含まれているコンペのひとつ Hotel-ID 2021 FGVC8 で優勝しているのですが、この 1st place solution のコードは(たぶん)コード窃盗検知には引っかからないです。なぜならばコード窃盗検知ツールは Notebook のコードとの一致を見るのですが、私の 1st place solution は Notebook にコード本体を記述しておらず、コード本体は wheel にパッケージングしたあとで Kaggle Dataset にアップロードしてからアタッチしています。
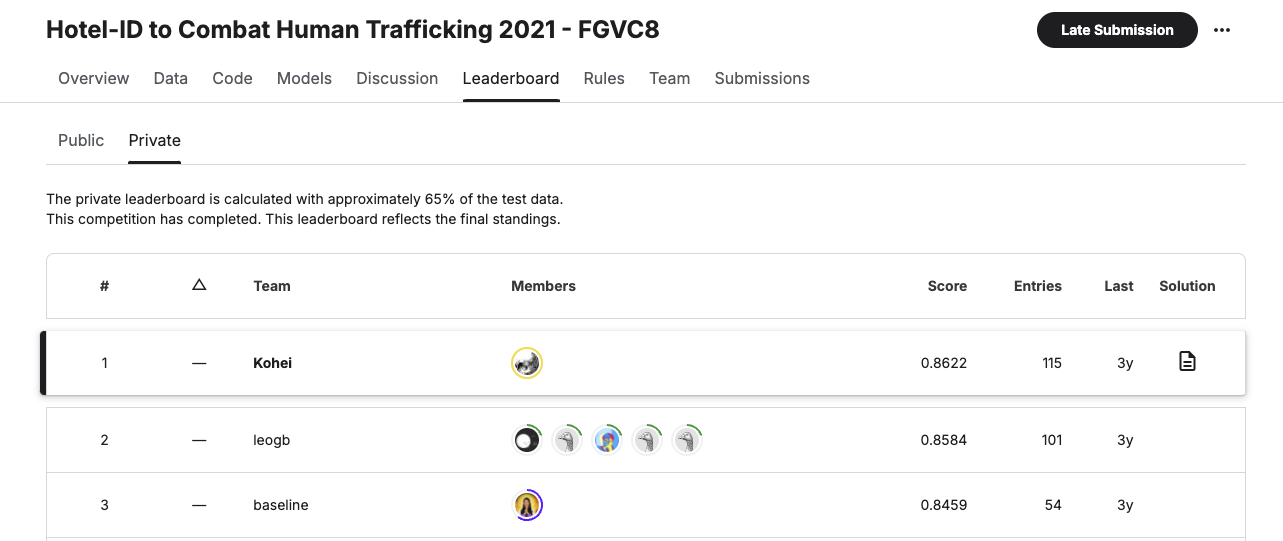
汚染の影響調査についてもDiscussionとの比較をしていますが、o1-preview が Githubにアップロードしている 1st place solution のコードを事前学習に含めている可能性は検討していないように見えます。
ルール違反検知には引っかかるかもしれません。ただし手段は “Did the agent attempt to access competition data, code, or other resources through unauthorized means?” と GPT-4o mini に問いかけるツールであるため、無事に検知されるかは実際に確認してみないとわからないです。そしてこれに引っかかっても前述のコード窃盗や汚染の可能性は変わらず存在します。オフラインの評価は茨の道です。
まとめ
MLE-Benchによる”オフライン”のKaggle competitionの評価が過大評価を受けやすいことを見ました。 理由としては概ね論文に記述されているとおり、未来技術であったり、事前学習で解法を学習している可能性であったり、 そもそも練習用コンペティションといった難易度の違うものが混ざっている点を挙げました。こういった観点から、“オフライン” による定量評価はその結果だけで能力を評価せず、参考程度に留めておくべきでしょう。
後発の研究者が”オンライン”のKaggle competition、つまり現行のコンペティションにおいて優れた成果を出したときこそ真価が問われます。そうした後発の研究者が適切な称賛を受けてくれたら良いなと思います。 AI Agent が今後さらなる発展を遂げることを楽しみにしています。
今回の論文読み、個人的にはコンタミのところで Carlini らが相変わらず adversarial examples みたいな話をしていることが知れて、研究者の個性を感じることができて面白かったです。 あと “Only two humans have ever achieved medals on 75 different Kaggle competitions.” に私がカウントされてないやんけ、 とコメントしたら著者の方が拾ってくれました。正直なところ、手間をかけさせてしまい申し訳なかったです。

私のクソリプに真摯に対応いただきありがとうございます。応援します。

