LLMの訓練データの透明性については New York Times と OpenAI の著作権訴訟が記憶に新しい。 あるターゲットテキストが LLM の fine-tuning の訓練データとして使われているか判別するメンバーシップ推論攻撃 (Membership Inference Attack; MIA) の論文が面白かったので、思い出す用にメモを記録する。
論文の提案手法では、対照的な言い換え表現を用いることで、ターゲットテキスト周辺の確率分布の変動を近似的に捉えようとしている。 LLMが特定のテキストを記憶 (LLM Memorization) している場合、そのテキストは「局所的な最大値に位置している」傾向がある。 提案手法はこれの近似的な検出方法になっているという理論的背景との繋がりが面白かった。NeurIPS’24 採択論文。
https://arxiv.org/abs/2311.06062
ざっくり要約
手法自体はシンプルなので下図の全体像をみるとだいたい想像がつく。
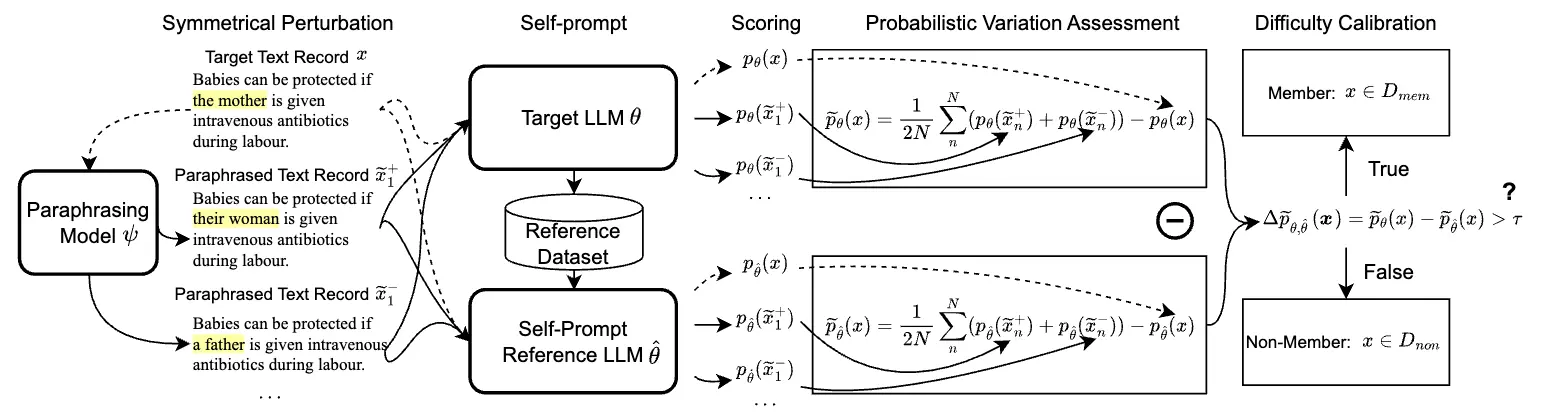
順番に、
- 下準備:ターゲットLLM からリファレンスデータセットを生成する
- 下準備:リファレンスデータセットを学習してリファレンスLLM を作成する
- ターゲットテキスト の対照的な言い換え表現 , を作る
- ターゲットLLM, リファレンスLLM で推論。提案手法の式によるスコアリング
- スコアの差がしきい値 以上であれば、ターゲットLLMの訓練データと判定する
という流れ。
先行研究と提案手法の関係
この提案手法 SPV-MIA は Reference-based MIA の一種である LiRA (likelihood ratio attack) を改良した手法。LiRA ではターゲットLLMとリファレンスLLMを用いて尤度比を計算し、ターゲットデータのメンバーシップを推定する。SPV-MIA では確率的変動(Probabilistic Variation)という新しい指標を用いてメンバーシップを推定する。確率的変動は、ターゲットテキストに対する対照的な言い換え表現(Symmetrical Perturbation)を用いて、確率分布の形状の変化を捉えることで判別する。
既存研究では、リファレンスLLMを学習するために必要となる「ターゲットドメインと同様のデータセット」の用意が難しいという問題点があった。この論文では、ターゲットLLMからデータを生成し(self-prompt)、リファレンスデータセットを構築する。このリファレンスデータセットからリファレンスLLMを構築して用いることで、メンバーシップを推論する際のバイアスを軽減する(Practical Difficulty Calibration; PDC と呼んでいる)。
ここでメモすること
この論文メモでは、以下のポイントを取り出してメモする。
-
Memorization は信頼性の高いメンバーテキスト検出の指標として適している (4.3)
-
Memorization による傾向に基づいて確率的変動が導出されるロジック (4.3)
-
実験結果によって示唆されること (5, A.5.1)
Memorization は信頼性の高いメンバーテキスト検出の指標として適している (4.3)
この論文では、Overfitting と LLM Memorization の違いを以下の観点で整理している。
発生時期 :Overfitting は LLMの検証セットに対する perplexity が上昇し始める最初のエポックで発生すると定義されている。一方で、Memorization はそれよりも早く始まり、ほぼ全ての訓練フェーズを通して持続する。
有害性 :Overfitting は機械学習においてほぼ普遍的に有害な現象として認識される。Memorization は必ずしも有害ではなく、QAタスクには不可欠である。
回避の難しさ :Memorization は Overfitting よりもはるかに早く発生するため、early stoppingを用いて Overfitting を防止しても、依然としてMemorizationは起こる。Memorizationは、機械学習モデルが最適な汎化を達成するためには不可避な現象。Memorizationは特定のLLMタスクに不可欠であるため、特定の意図しないMemorizationのみを軽減することは容易ではない。
このため、Memorization は有害であるとして回避されることもなく、そもそも回避が難しいので、Overfittingよりも信頼性の高いメンバーテキスト検出の指標になると主張している。 先行研究はターゲットモデルがOverfittingしているという前提に強く依存しているのに対して、提案手法は Memorization における傾向を出発点として定式化している。
LLMのMemorizationは、訓練データに含まれていたテキスト(メンバーテキスト)が、その周辺の確率分布において局所的な最大値を持つという傾向を生み出すと解釈できる(引用文献)。提案手法はこの傾向に着目し、対照的な言い換え表現を用いることでターゲットテキスト周辺の確率分布の変動を捉える。「局所的な最大値に位置しているかどうか」を判断することで、メンバーシップ推論攻撃を実現している。
Memorization による傾向に基づいて確率的変動が導出されるロジック (4.3)
LLMは、訓練データのテキストの同時確率を最大化するように学習される(CLM)。そのため、訓練データに含まれていたテキスト(メンバーテキスト)は、LLMにとって生成されやすい、確率的に「特別な」位置にあると考えることができる。この「特別な」位置は、確率分布において局所的な最大値として現れると仮定する。確率的変動は、この局所的な最大値を検出するために設計された指標。
局所的な最大値を検出する道具として、二階偏微分による多変数関数の極値判定(second partial derivative test)を使う。極大値を識別するという目的のために、Hessian 行列(二階偏微分の行列)が負定値であることを確認する必要がある。でもこれはメンバーテキストが厳密に極大値に該当しない場合があることを考慮して、判定方法を緩和する。具体的には、様々な摂動方向 に対する二階偏微分の期待値として計算する(心の声:けっこう大胆な緩和をしているなあ)。すなわち、
は、Hessian 行列と方向ベクトル を用いて、 における確率分布の 方向への曲率を表す。 そのため は、ターゲットテキスト が、確率分布のピーク(局所的最大値)に位置するかどうかを判断する指標となる。
様々な摂動方向 に対する二階偏微分(曲率)の期待値が大きくなるのは、複雑な形状をしており、局所的な曲率が大きくなる領域が多数存在する場合と解釈できる。 逆に期待値が小さくなるのは曲率が小さく平坦な領域。そのように考えると、様々な摂動(テキストを過ごしだけ動かす) に対して大きく反応することの指標となるので、LLM Memorization による「特別な」位置を捉える指標として適しているように見える。
でもって二階偏微分は計算コストが高いため、論文では対照的な言い換え表現を用いて近似的な計算を行う。
が必要であり、 はサンプリングされた摂動方向と考えることができる。したがって、 は、データ分布における の対称的な隣接テキストレコードのペアと考えることができる。係数 を省略することで、以下のように再定式化できる。
, は、言い換えモデルによってサンプリングされた対称的なテキストペアであり、高次元空間における元のテキスト をわずかに言い換えたもの。例えば、
-
ターゲット:陣痛中に”母親”が抗生物質を静脈内投与されれば、赤ちゃんを守ることができる
-
言い換え:陣痛中に”女性”が抗生物質を静脈内投与されれば、赤ちゃんを守ることができる
-
対照的な言い換え:陣痛中に”父親”が抗生物質を静脈内投与されれば、赤ちゃんを守ることができる
こういった言い換えによってターゲットテキストらしい反応を探る。 が必要であるため、文レベルの言い換えは控えめにする必要があり、上述のように特定のトークンだけが変形されたテキストを作る。
実験結果によって示唆されること
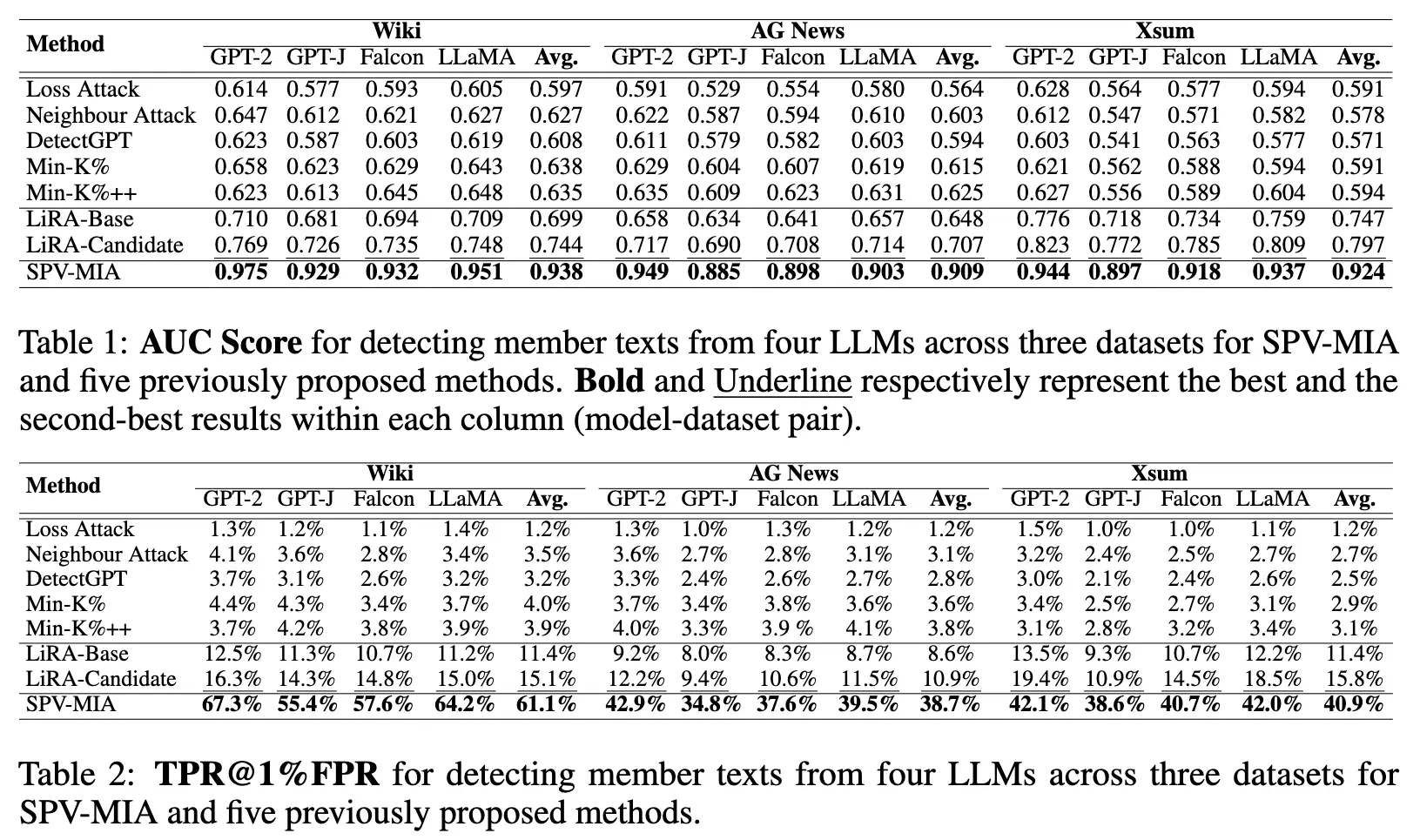
既存のMIAとオープンソースな LLM にて比較評価。オープンソースLLMの GPT-2, GPT-J, Falcon-7B, LLaMA-7B で実験している。リファレンスモデル不要の Loss Attack やリファレンスベースの LiRA に対してAUCスコア、TPR@1%FPRの両方で大幅に優れた性能を示している。
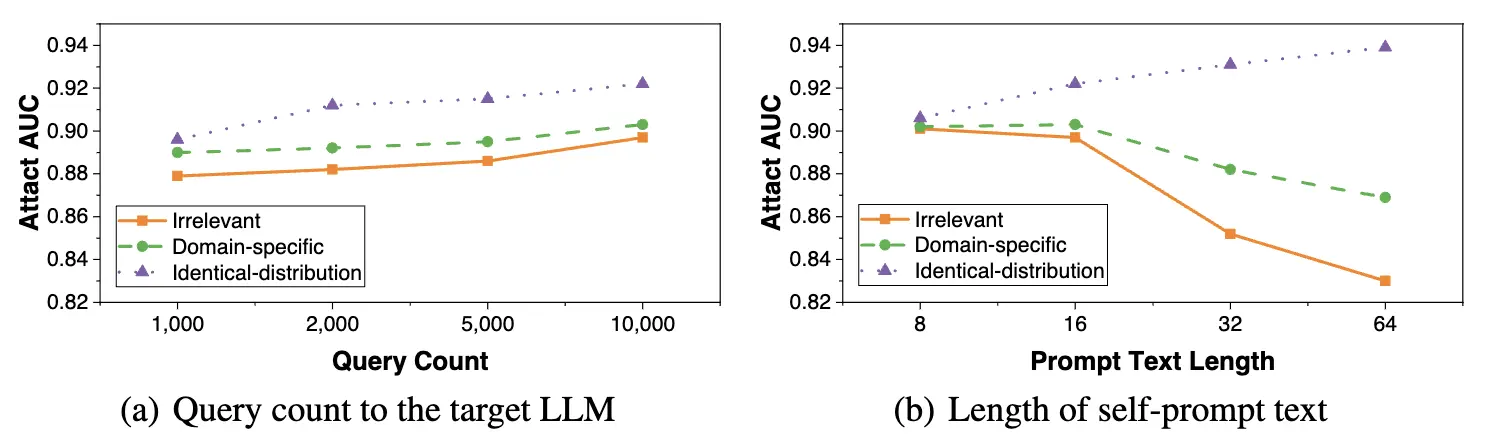
ターゲットLLM にクエリを投げる回数
self-prompt を用いてリファレンスデータセットを作るためには、データの数だけターゲットLLMにクエリを投げる必要がある。下図(a)は、クエリを投げる量(リファレンスデータセットのサイズ)と Attack AUC の関係を示している。わずか1,000回のクエリでも、10,000回の場合と遜色ない攻撃性能を達成できることを示している。限られたAPIアクセス回数でも有効な手法であると言える。
self-prompt text の長さについても実験がされている。長いほど生成されるテキストに多様性と特異性の影響を与える。下図(b)は、非常に短いトークン数 8 でも高い攻撃性能を示している。また同一分布のデータセットからのテキストでは、テキスト長が長いほどよく、無関係なデータセットであったり固有のデータセットであれば長すぎると悪化する。 この結果は、できるだけターゲットLLMの訓練セットのデータ分布に近いサンプルを生成することが重要であることを示唆している。
どのモジュールが性能向上へ貢献しているか
PDC (Practical Difficulty Calibration) と PVA (Probabilistic Variation Assessment) のそれぞれを削除した場合の性能を評価した Ablation study。PDC はself-promptによるリファレンスLLM構築。PVA は確率的変動をそれぞれ指す。結果は以下の通り。
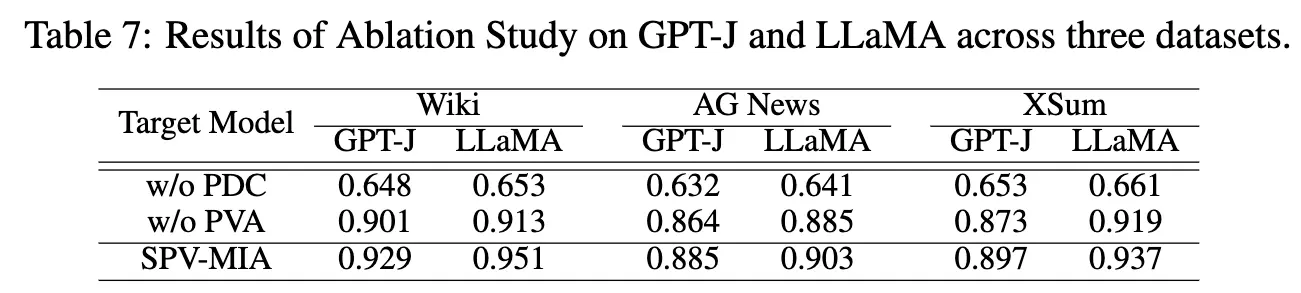
テーブルから、両方とも性能向上に寄与していることがわかる。特に PDC が重要な役割を果たしており、PVA なしでも有効な攻撃手法として機能することを示唆している。PVA は対照的な言い換え表現をLLMに入力するため 3 倍の LLM へのリクエストになる。それを考えると、API アクセスを節約しても効果的な攻撃であることを示唆している。(心の声:え!あれだけ頑張って式変形を追ったのにあんまりだ!)
所感
確率的変動について、ちゃんと理論的な説明付けがされていてロジカルで面白かった。ここではメモしていないが対称的なテキストペアを作成するための言い換え表現の生成アルゴリズムのほうは、だいぶ泥臭いエンジニアリング的な発想で開発されているように見えた。局所的なピークを効率よく取り出す言い換え表現の生成は工夫の余地がたくさんありそうで、これも面白そう。
一方で、確率的変動は API アクセスを 3 倍にする重い方法であるにもかかわらず、Ablation study を見るとあまり大きな貢献でないことが見えた。この点は少し残念。 (※PVAの言い換え表現は1つでも十分強力という主張ではあるが、の摂動を作ることができるから厳密には1+2N倍のコストとなる)

