Kaggle の Code Competition で Jupyter Notebook 形式のコードを提出する機会が多くなってきました。開発効率を考えるとブラウザを使うことなくサブミッションを作成したり更新する作業フローが欲しくなります。ブラウザをなるべく使わない作業フローを紹介し、Kaggle に必要な機能が何かを考察します。
📢 ご案内
この記事では kaggle コマンドの実行が多用されています。ターミナルを開いて kaggle コマンドを打つのは実際ちょっと手間です。そのためVSCode拡張を開発してショートカットキーで操作できるようにしました。Kaggleコンペ用のVSCode拡張を開発した の記事にて紹介しているので、こちらもご参照ください。
まとめ
長いので3行でまとめると、
-
実装するコードは Dataset として Kaggle にアップロードする
-
コンペに投稿する Notebook は Dataset にあるコードを呼び出すだけ
-
Notebook も Dataset も VSCode で更新して Kaggle CLI 経由でアップロードする
ということです。
モチベーションはコードベースの大規模化
Kaggle の solution は大規模化していくことがあります。例えば icecuber による ARC 1st place solution は Kaggle notebook 上でソースコードをデータセットとしてアタッチして、その中にある Makefile で C++ のプログラムをコンパイルして、外部プロセス呼び出しによってコンパイルされたバイナリを実行します。
Jupyter Notebook はプログラムを書く開発環境としては機能が不十分です。VS Code と異なり Github Copilot もありませんし、Linter, Formatter なども十分に使えません。小さな使い捨ての実験コードであれば Notebook でも大きな問題にはなりません。しかし Kaggle コンペティションの最終的なソリューションはそうなっていないことが多いです。
であるならば、コード管理をしっかりして、テストコードを書いたり、VSCode などの開発環境からコンペに投稿する作業フローを効率化したいというモチベーションが強くなります。
コードコンペティションの作業フロー
この記事で紹介する作業フローの全体図は以下のようになります。
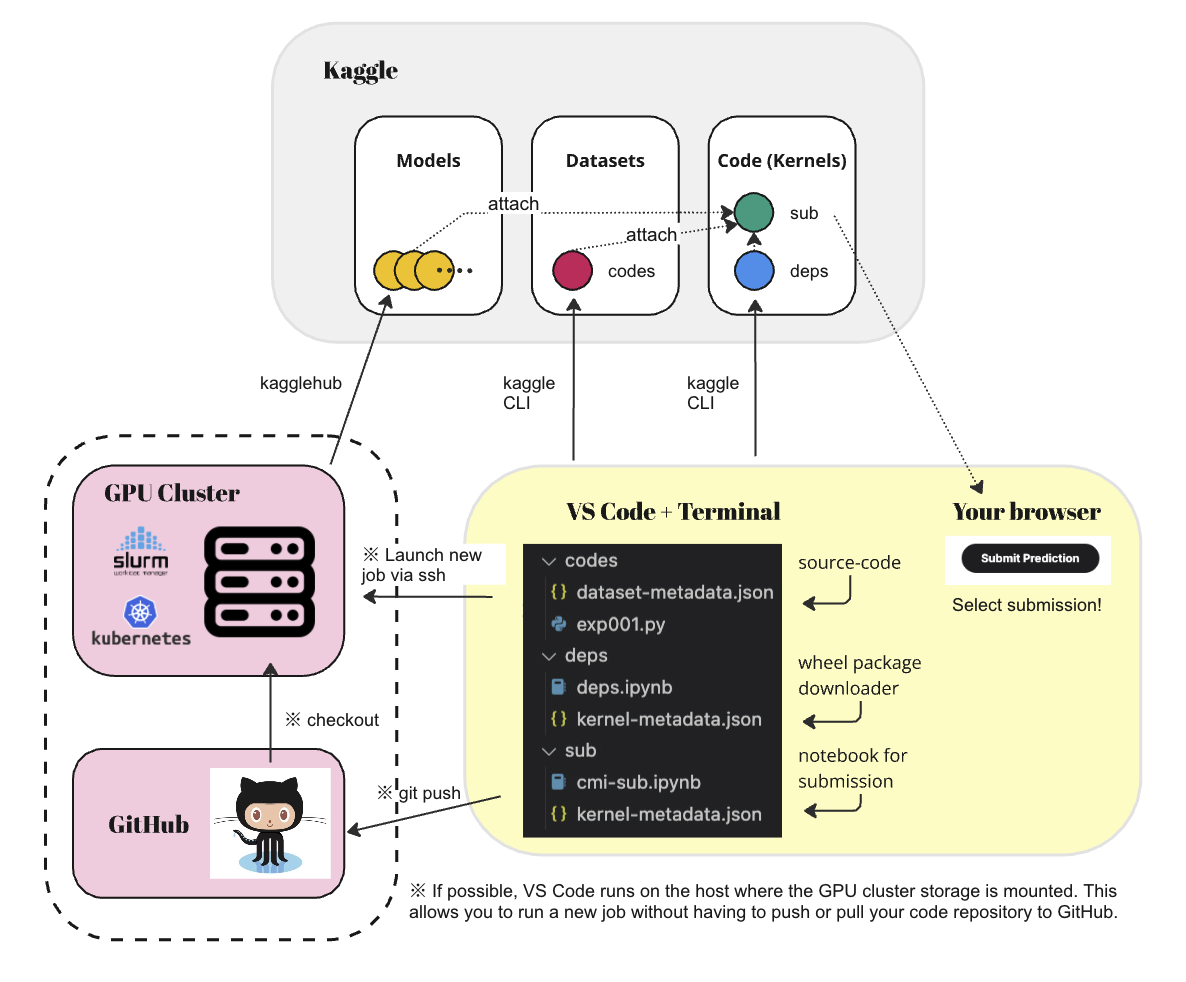
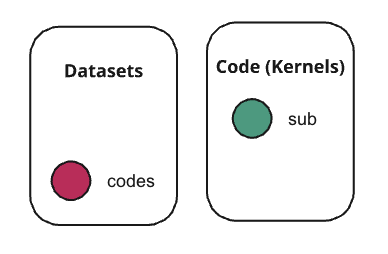
コードは VSCode の世界で扱う。Kaggle との操作をブラウザではなく VSCode 上の Terminal から行います。以下の 4 つの操作がメインとなります。
- ● codes Dataset に対する操作。VSCode で実装したコードを Kaggle CLI 経由でアップロードする。
- ● deps Notebook に対する操作。VSCode で wheel ダウンロードのコマンドを記述。Kaggle CLI 経由でアップロードする。
- ● モデルの重みファイル に対する操作。訓練スクリプトから kagglehub 経由で Kaggle Models にアップロードする。
- ● sub Notebook に対する操作。上述の3つをアタッチしてコンペに投稿ための Notebook としてアップロードする。
GPU クラスターと同じストレージをマウントしているホストで開発できる場合、コードをデプロイする手間が減るので、より効率的に作業を薦めることができます。VSCode から Remote SSH して Dev Container の中で開発するなどして、Kaggle と同様のマウントポイントを定義すると良いでしょう。このあたりは環境依存の話題であるため割愛します。
以降では具体的に過去コンペである “Child Mind Institute - Detect Sleep States” を例にして、手続きを説明します。ローカル開発環境に ./kaggle-cmi というディレクトリを作成し、その中で作業を進めます。
ubuntu@gpu:~/ws$ mkdir ./kaggle-cmi && cd ./kaggle-cmiVSCode の「フォルダを開く」から ./kaggle-cmi を開いて作業を進めます。
1. sub を新規作成(一度きり)
最初にコンペティションのサブに用いる ● sub Notebook を作成します。
まずサブディレクトリ ./sub を作成して、その中で Kaggle CLI によって ● sub Notebook の雛形を生成します。
ubuntu@gpu:~/ws/kaggle-cmi$ mkdir ./sub && cd ./sub
ubuntu@gpu:~/ws/kaggle-cmi/sub$ kaggle k init
ubuntu@gpu:~/ws/kaggle-cmi/sub$ cat ./kernel-metadata.json
{
"id": "confirm/INSERT_KERNEL_SLUG_HERE", # URLに使われる投稿用NotebookのID (confirm はユーザーアカウント名)
"title": "INSERT_TITLE_HERE", # Notebookのタイトル
"code_file": "INSERT_CODE_FILE_PATH_HERE", # アップロードする ipynb ファイルの名前
"language": "Pick one of: {python,r,rmarkdown}",
"kernel_type": "Pick one of: {script,notebook}",
"is_private": "true",
"enable_gpu": "false", # GPU の有効無効(デフォルトはP100っぽい)
"enable_tpu": "false",
"enable_internet": "true", # インターネットの有効無効
"dataset_sources": [],
"competition_sources": [],
"kernel_sources": [],
"model_sources": []
}kernel-metadata.json は例えば下記のように適時編集してください。
{
"id": "confirm/cmi-sub", # URLに使われる投稿用NotebookのID
"title": "cmi-sub", # Notebookのタイトル
"code_file": "cmi-sub.ipynb", # アップロードする ipynb ファイルの名前
"language": "python",
"kernel_type": "notebook",
"is_private": "true",
"enable_gpu": "true", # GPU を有効にする (今のデフォルトは P100 っぽい)
"enable_tpu": "false",
"enable_internet": "false", # インターネットを無効にする
"dataset_sources": [],
"competition_sources": [],
"kernel_sources": [],
"model_sources": []
}次に ipynb ファイルを作成します。Cmd-P でコマンドパレットを開いて “>new jupyter” と入力して新しい Notebook を作成します。ipynb の中身を以下のように書いてみます。
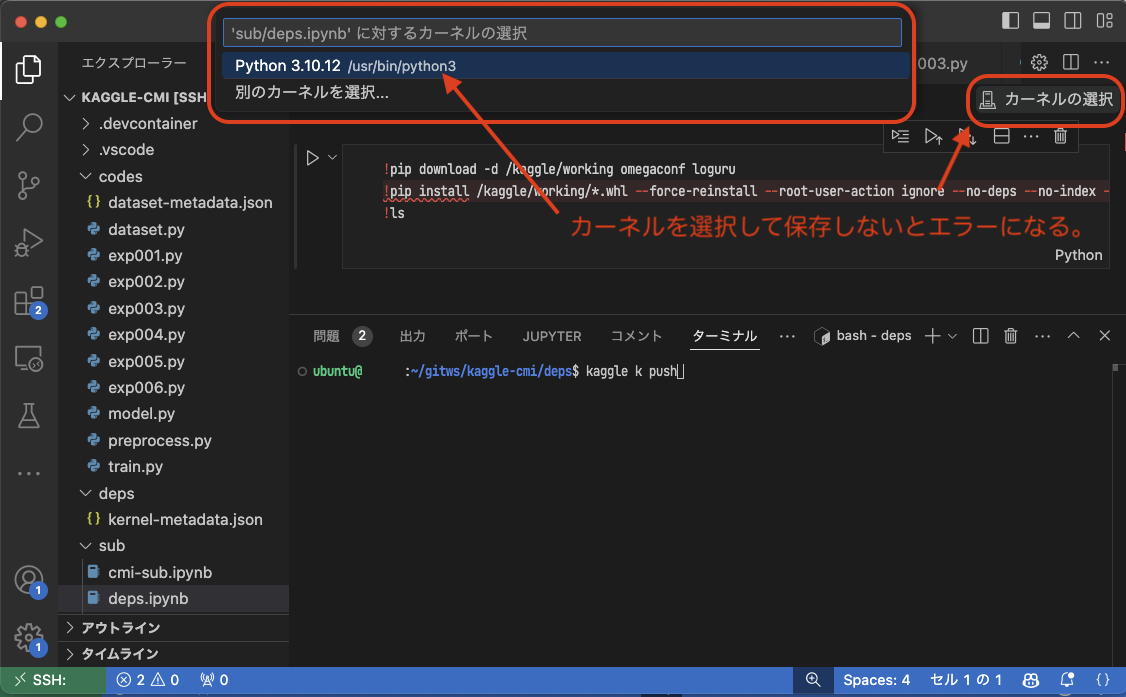
!ls /kaggle/inputファイルが用意できたら保存します。ファイル名は kernel-metadata.json で定義したものと同じファイル名 cmi-sub.ipynb とします。
ipynb ファイルのカーネルが選択されていない場合は選択して保存します。選択をすると、画面からは確認できませんが ipynb ファイルのメタデータに “kernelspec” という項目が追加されます。このメタデータなないと Kaggle に push したときに Non-interactive session での Notebook の実行でエラーが発生します。忘れず選択して保存しましょう。
編集した Notebook を Kaggle 上で反映させるためには kaggle k push コマンドを使います。
ubuntu@gpu:~/ws/kaggle-cmi/sub$ kaggle k push
Kernel version 2 successfully pushed. Please check progress at https://www.kaggle.com/code/confirm/cmi-subこれで ● sub Notebook の作成が完了しました。 Kaggle CLI で作成した Notebook を確認できます。
# -m は自分の作成した Notebook のみを表示するオプションです
# -s は検索キーワードを指定するオプションです
ubuntu@gpu:~/ws/kaggle-cmi/sub$ kaggle k list -m -s cmi-sub
ref title author lastRunTime totalVotes
--------------- ------- ------ ------------------- ----------
confirm/cmi-sub cmi-sub Kohei 2024-10-05 01:01:57 0confirm/cmi-sub というIDで ● sub Notebook が作成されています。作成した Notebook はローカル開発環境の VSCode から更新していきます。
メタデータの kernel-metdata.json を編集してコンペに投稿可能なように設定しておきます。competition_sources をキーとするリストにコンペの名前を追加すると、Notebook を保存して実行した際にコンペティションのデータセットがアタッチされ、コンペと関連付けがされます。
< "competition_sources": [],
----
> "competition_sources": [
> "child-mind-institute-detect-sleep-states"
> ],編集した Notebook を Kaggle 上で反映させるために kaggle k push コマンドを使います。
ubuntu@gpu:~/ws/kaggle-cmi/sub$ kaggle k push
Kernel version 2 successfully pushed. Please check progress at https://www.kaggle.com/code/confirm/cmi-subこれで ● sub Notebook の更新が完了しました。ターミナルに出てくるURLを開くと作成した Notebook が確認できます。Notebook の実行ステータスは kaggle k status <NotebookのID> で確認できます
2. codes を新規作成 (一度きり)
次にコンペで用いるコードをまとめた ● codes Dataset を作成します。この操作も一度きりの作業です。
./codes というディレクトリを作成し、ここでコードを書いていきます。
ubuntu@gpu:~/ws/kaggle-cmi/sub$ mkdir ../codes && cd ../codesデータセットの初期化を Kaggle CLI で実行します。 すると ● codes Dataset を定義するメタデータの雛形が出力されます。
ubuntu@gpu:~/ws/kaggle-cmi/codes$ kaggle d init
Data package template written to: /home/ubuntu/ws/kaggle-cmi/codes/dataset-metadata.json
ubuntu@gpu:~/ws/kaggle-cmi/codes$ cat dataset-metadata.json
{
"title": "INSERT_TITLE_HERE",
"id": "confirm/INSERT_SLUG_HERE",
"licenses": [
{
"name": "CC0-1.0"
}
]
}編集してデータセット名などを設定します。
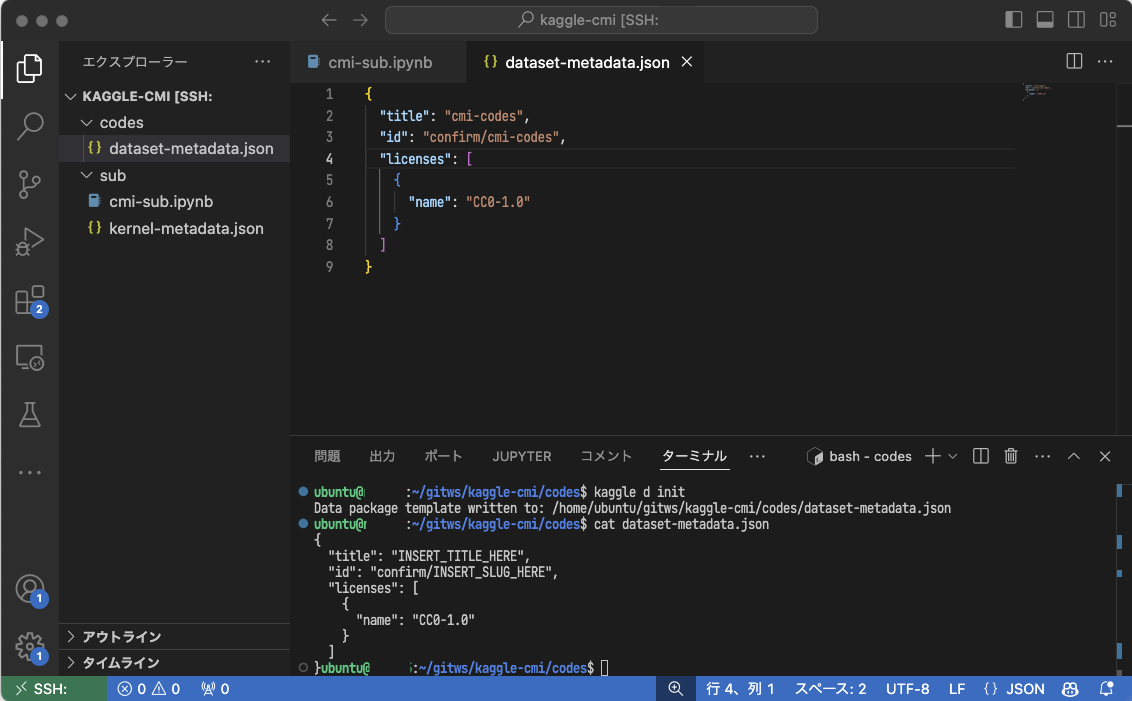
# dataset-metadata.json を編集する
# ※ 名前の長さや記号の扱いには制約があるので注意
$ cat dataset-metadata.json
{
"title": "cmi-codes", # これはデータセットのタイトル
"id": "confirm/cmi-codes", # これは URL に使われるID
"licenses": [
{
"name": "CC0-1.0"
}
]
}データセットの作成には最低でも一つのファイルが必要です。最もシンプルなコードをテストのために作成します。ここでは hello.py というコードを作成してみます
ubuntu@gpu:~/ws/kaggle-cmi/codes$ cat > hello.py
print("Hi")
ubuntu@gpu:~/ws/kaggle-cmi/codes$ ls
dataset-metadata.json hello.py準備ができたので ● codes Dataset としてアップロードします。
ubuntu@gpu:~/ws/kaggle-cmi/codes$ kaggle d create -p .
Starting upload for file sample_submission.py
(snip)
Your private Dataset is being created. Please check progress at https://www.kaggle.com/datasets/confirm/cmi-codes無事にアップロードされました。CLI からデータセットがアップロードされていることを確認してみましょう。
# -m は自分の作成した Dataset のみを表示するオプションです
# -s は検索キーワードを指定するオプションです
$ kaggle d list -m -s cmi-codes
ref title size lastUpdated downloadCount voteCount usabilityRating
----------------- --------- ---- ------------------- ------------- --------- ---------------
confirm/cmi-codes cmi-codes 5KB 2024-10-06 03:21:51 0 0 0.25無事にアップロードされていることを確認できました。
3. 学習済みの重みファイルをアップロード (kagglehub)
学習済みの重みファイル●は、 訓練用コードから kagglehub モジュールを経由して Kaggle Models にアップロードすると良さそうです。
メタデータを作成して編集する必要がなく、一回の関数呼び出しでモデルの新規作成とアップロードをしてくれます。以下のようなコードを訓練用コードの適切な場所に追加しておきましょう。
import kagglehub
handle = "confirm/cmi-models/pytorch/exp-001"
local_dataset_dir = "./data/working/models/exp001"
kagglehub.model_upload(handle, local_dataset_dir, ignore_patterns=["ckpt*.pth"])モデルのアップロードは以下 Kaggle CLI から確認できます。 モデルバージョンを確認する手段がないため、このへんは不便を感じます。
$ kaggle m list --owner confirm -s cmi-models
id ref title subtitle author
------ ------------------ ---------- -------- ------
131688 confirm/cmi-models cmi-models Kohei現状では https://www.kaggle.com/work/models からモデルを確認するほうが確実かもしれません。
4. 必要に応じて codes と sub を更新
ベースラインとなるコードを作成し、コンペに投稿してスコアの出る ● sub Notebook を作成してみましょう。これはコードベースとなる ● codes Dataset を更新し、● sub Notebook もコードを呼び出すために更新するという作業になります。
codes を更新
以下にようなベースラインを実装してみます。
import pandas as pd
test = pd.read_parquet("/kaggle/input/child-mind-institute-detect-sleep-states/test_series.parquet")
onset = test[test["timestamp"].str.slice(11,19)=="23:00:00"].set_index("series_id")["step"]
wakeup = test[test["timestamp"].str.slice(11,19)=="06:30:00"].set_index("series_id")["step"]
sub = pd.concat([
onset.reset_index().assign(event="onset"),
wakeup.reset_index().assign(event="wakeup"),
])
sub["score"] = 0.5
sub.sort_values(["series_id","event"], ascending=[0,1]) # type: ignore
sub.reset_index(drop=True, inplace=True)
sub["row_id"] = sub.index
sub = sub[["row_id","series_id","step","event","score"]]
sub.to_csv("submission.csv", index=False)このベースラインを ./codes/exp001.py として保存して ● codes Dataset を更新します。
ubuntu@gpu:~/ws/kaggle-cmi/sub$ cd ../codes
ubuntu@gpu:~/ws/kaggle-cmi/codes$ ls
exp001.py dataset-metadata.json hello.py
# -r はディレクトリを zip で圧縮してアップロードします(デフォルトはスキップ)
ubuntu@gpu:~/ws/kaggle-cmi/codes$ kaggle d version -m 'update' -r zip
Starting upload for file exp001.py
(snip)
Dataset version is being created. Please check progress at https://www.kaggle.com/confirm/cmi-codessub のメタデータを編集
● sub Notebook に ● codes Dataset をまだアタッチしていないので、メタデータ ./sub/kernel-metadata.json を編集してアタッチします。
"dataset_sources": [
"confirm/cmi-codes"
],ほかにも必要な Dataset があれば、メタデータに追加していきます。
Kaggle Models にモデルをアップロードしているならば、“model_sources” に追加します。Models は owner, model-slug, framework, instance-slug, version-number それぞれの情報をスラッシュ区切りで指定する必要があります。たとえば以下のように指定します。
"model_sources": [
"confirm/cmi-models/pytorch/exp-001/1"
]このとき、指定したモデルは以下にマウントされます。
/kaggle/input/cmi-models/pytorch/exp-001/1sub の ipynb ファイルの中身を更新
● codes Dataset に追加した exp001.py を実行するように、● sub Notebook の内容を更新します。以下のようにマジックコマンドを使ってプログラムを呼び出すことにします。
!PYTHONPATH=/kaggle/input/cmi-codes \
python /kaggle/input/cmi-codes/exp001.py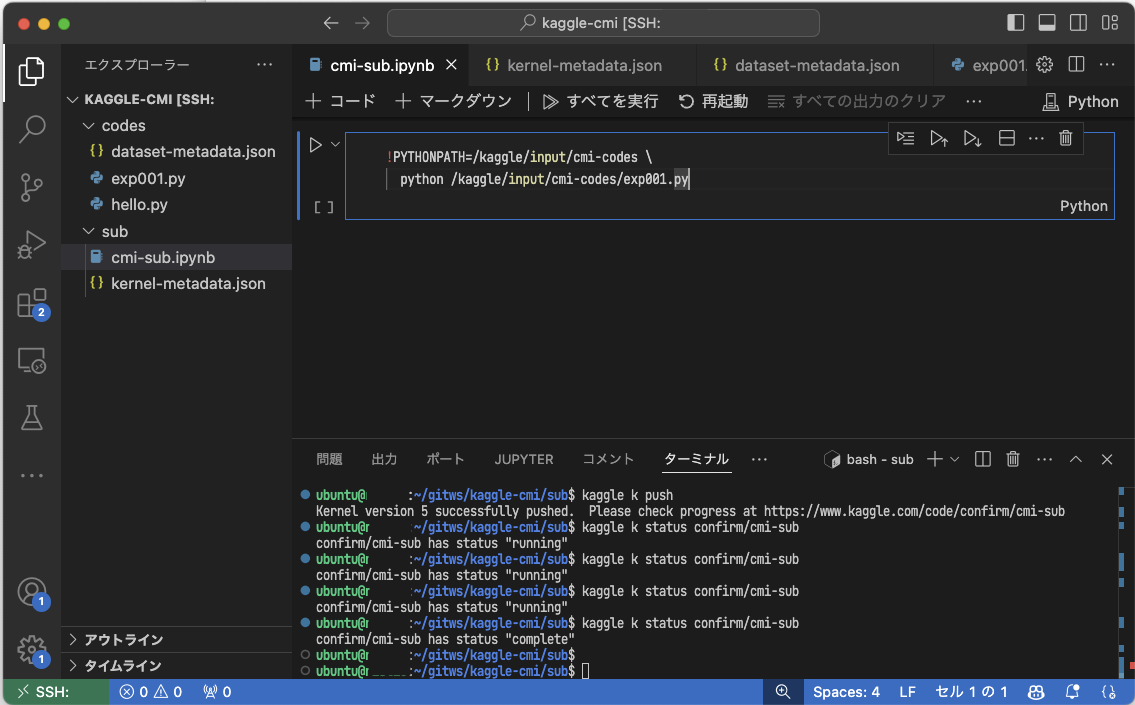
最後にこの ● sub Notebook を push すればコンペに提出できるようになります。
ubuntu@gpu:~/ws/kaggle-cmi/codes$ cd ../sub
ubuntu@gpu:~/ws/kaggle-cmi/sub$ kaggle k push
Kernel version 4 successfully pushed. Please check progress at https://www.kaggle.com/code/confirm/cmi-sub
# Notebook の実行ステータスは kaggle k status で確認できます
ubuntu@gpu:~/ws/kaggle-cmi/sub$ kaggle k status confirm/cmi-sub
confirm/cmi-sub has status "complete"最初は大変ですが、一度準備ができたら VSCode から ● codes Dataset に対して kaggle d version -m ‘update’ -r zip で更新して、● sub Notebook に対して kaggle k push で更新していくだけです。
必要な wheel パッケージを出力してアタッチ
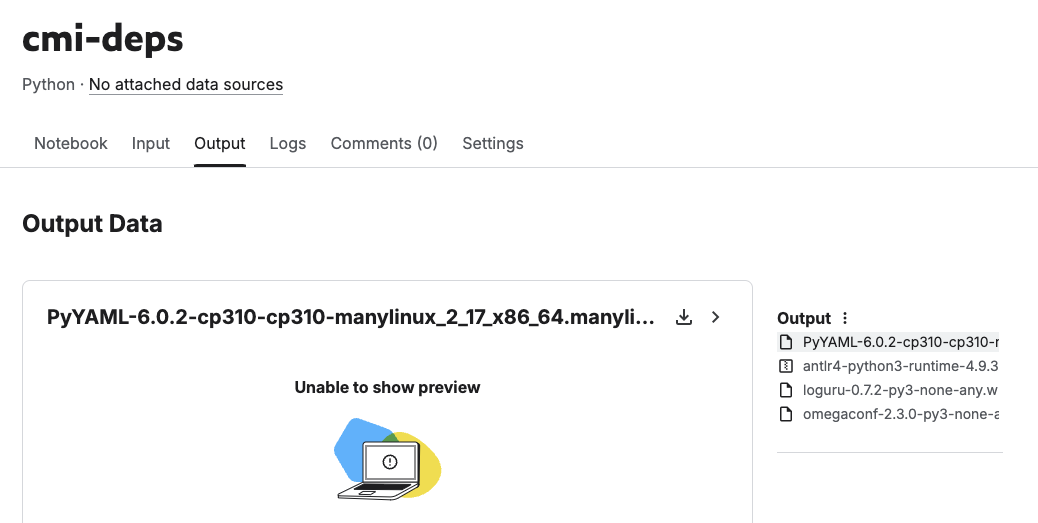
コンペに投稿する ● sub Notebook はオフライン環境で実行されなくてはいけません。そのため追加で必要な Python パッケージがある場合、別途ダウンロードしておいて、● sub Notebook にアタッチする必要があります。
ここではコンペに必要な依存ファイルを出力として保存する ● deps Notebook の作成手順を紹介します。
まず ./deps というディレクトリを作成して、● deps Notebook を作成するための雛形となるメタデータを作成します。
ubuntu@gpu:~/ws/kaggle-cmi/sub$ mkdir ../deps && cd ../deps
ubuntu@gpu:~/ws/kaggle-cmi/deps$ kaggle k initメタデータの ./deps/kernel-metadata.json は以下のように定義します。
{
"id": "confirm/cmi-deps", # <アカウント名>/<Notebook名>
"title": "cmi-deps", # Notebookのタイトル
"code_file": "deps.ipynb", # 作成するipynbのファイル名
"language": "python",
"kernel_type": "notebook",
"is_private": "true",
"enable_gpu": "false",
"enable_tpu": "false",
"enable_internet": "true", # ダウンロードするので有効にする
"dataset_sources": [],
"competition_sources": [],
"kernel_sources": [],
"model_sources": []
}Cmd-P でコマンドパレットを開いて “>new jupyter” と入力して新しい Notebook を作成します。ここではファイル名を deps.ipynb として保存します。
!pip download -d /kaggle/working omegaconf loguru
!pip install /kaggle/working/*.whl --force-reinstall --root-user-action ignore --no-deps --no-index --find-links /kaggle/working
!lsipynb ファイルのカーネルが選択されていない場合は忘れず選択して保存しましょう。
Kaggle CLI で Notebook アップロードします。kaggle k push コマンドを使います。
ubuntu@gpu:~/ws/kaggle-cmi/deps$ kaggle k push
Kernel version 7 successfully pushed. Please check progress at https://www.kaggle.com/code/confirm/cmi-depsこれで wheel パッケージを出力するための Notebook が作成されます。
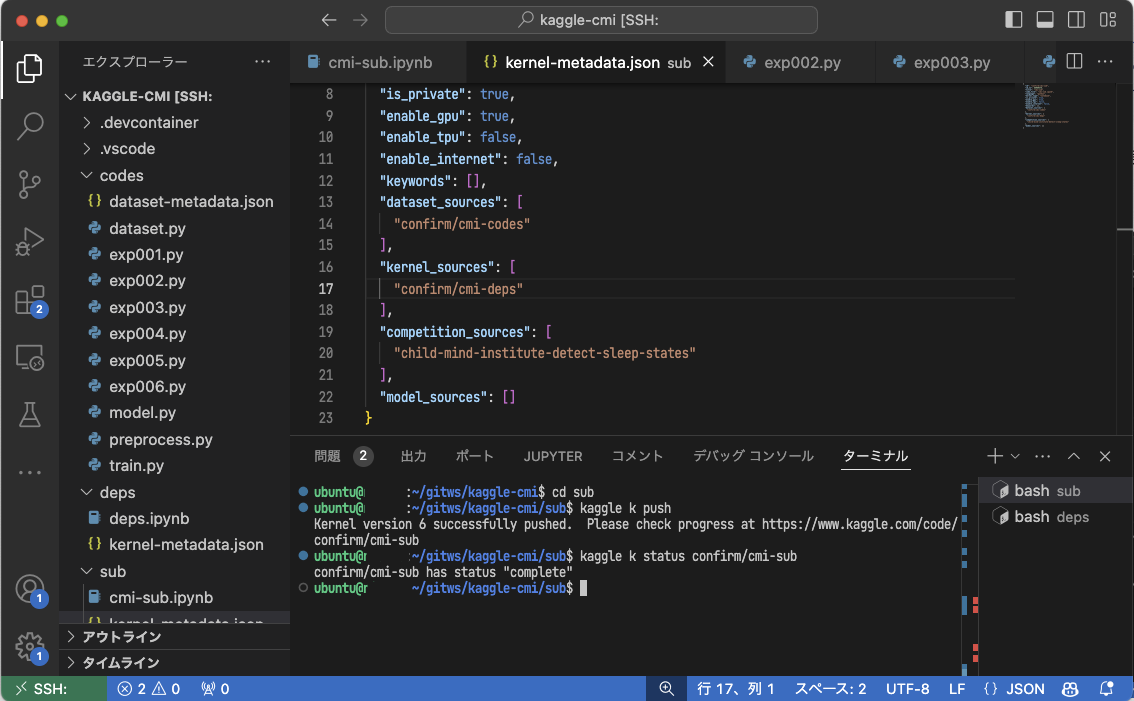
最後に ● deps Notebook の ID を ● sub Notebook の入力リソースとして追加します。メタデータ ./sub/kernel-metadata.json を以下のように編集します。
16c16,18
< "kernel_sources": [],
---
> "kernel_sources": [
> "confirm/cmi-deps"
> ],● sub Notebook の中身である cmi-sub.ipynb に、wheel パッケージをインストールするコマンドを追加しておきます。
!pip install /kaggle/input/cmi-deps/*.whl --force-reinstall --root-user-action ignore --no-deps --no-index --find-links /kaggle/input/cmi-deps
!PYTHONPATH=/kaggle/input/cmi-codes python /kaggle/input/cmi-codes/exp001.pyこれでパッケージをインストールして、その後にメインのコードを実行する ● sub Notebook ができます。
余談:kagglehub はコンペ投稿用の Notebook に使えない
kagglehub の機能を使うことで、Kaggle notebook に Kaggle dataset のアタッチが可能となります。

とても便利そうな kagglehub ですが、現時点 (2024/10/05) では Interactive session でしか kaggle dataset のアタッチはできない。コンペティションに用いる Notebook は immutable な Non-interactive session で実行されるため、kagglehub によるアタッチができないことに注意が必要です。
これが Non-interactive session で実行可能になれば、● sub Notebook にアタッチするデータセットやモデルを直接記述可能になります。バージョン指定など細かい指定もできるようになりそうです。こういった要望があることは Kaggle にも伝わっているので、今後のアップデートに期待です。
kaggle へのリクエストと考察
作業フローを整備する上で、問題点がいくつか見つかった。改善する上で必要と思える Kaggle の機能について考察する。
コードコンペの投稿の実行時間
優先度:高い
Kaggle のコードコンペでは実行時間の制限がある。コンペティションに投稿してテストデータでの評価が行われる際、どの程度の実行時間がかかっているのか知る方法がほしい。現状はタイムアウトしているか否かしか情報がない。しょうがないのでスクリプトを書いて計測しているが、これはあるべき姿ではないはず。
Kaggle Models の Variants や Versions をリストする手段
優先度 : 普通
Kaggle CLI には Kaggle Models に対するコマンドも備わっているが、貧弱であるように見える。 たとえばアップロードしたモデルの variants や versions をリストする方法がない。これが可能になれば、作成されたはずのモデルが存在するかどうがを確認できるので便利になる。
Kaggle CLI からコードコンペの投稿
優先度:普通
Kaggle ではコードコンペが主流になりつつある。しかし Kaggle CLI の kaggle competitions submit はファイルを直接アップロードする方法しかサポートしていない。コードコンペティションにおいても、kaggle competition submit コマンドから Kaggle notebook のリファレンス名とバージョンを指定することで投稿できるようにしてほしい。
なんだかんだエラーが発生してログを確認するためにブラウザ操作をすることも多いので、そこまで必須というわけではない。ボタンをなんどか押せば投稿できるし。
kernel-metadata.json の GPU 選択の項目
優先度:低い
GPU を有効・無効にする項目はあるが、GPUカードの種類(P100 とか)を指定をする項目がない。追加してほしい。
Notebook にアタッチするデータセットのバージョン指定
優先度:低い
kernel-metadata.json にはアタッチするデータセットのバージョンを指定する方法がない。Notebook を push したとき、指定されたリソースの最新のバージョンがアタッチされる仕様になっている。あまり困ることはない。

