Kaggleのプロダクトアナウンスを追っていると、最近はコンペティション以外の機能を積極的に強化しているところが見えます。特に、AIモデルのベンチマークや評価のためのプラットフォームとして、興味深いアナウンスが次々に発表されました。具体的には、
-
Kaggle Benchmark のローンチ
-
HuggingFaceやColabとの連携強化
-
kagglehubや Kaggle Models の機能強化 -
生成AI活用の短期集中オンラインコース
など様々なトピックがあります。その中でも、Kaggle Benchmark について解説し、これに関連して ICML’25 に採択されたポジションペーパーについて紹介します。
Kaggle による信頼性の高いベンチマーク
Kaggle Benchmark がローンチされました。Kaggle Benchmark は AI モデルの能力を評価するための新しいプラットフォームとして位置づけられています。Kaggle コンペティションのような個人・チームのランク付けではなく、モデルのランク付けとなる点が大きく違います。
以下はベンチマークの一例としてSciCode のベンチマークページです。
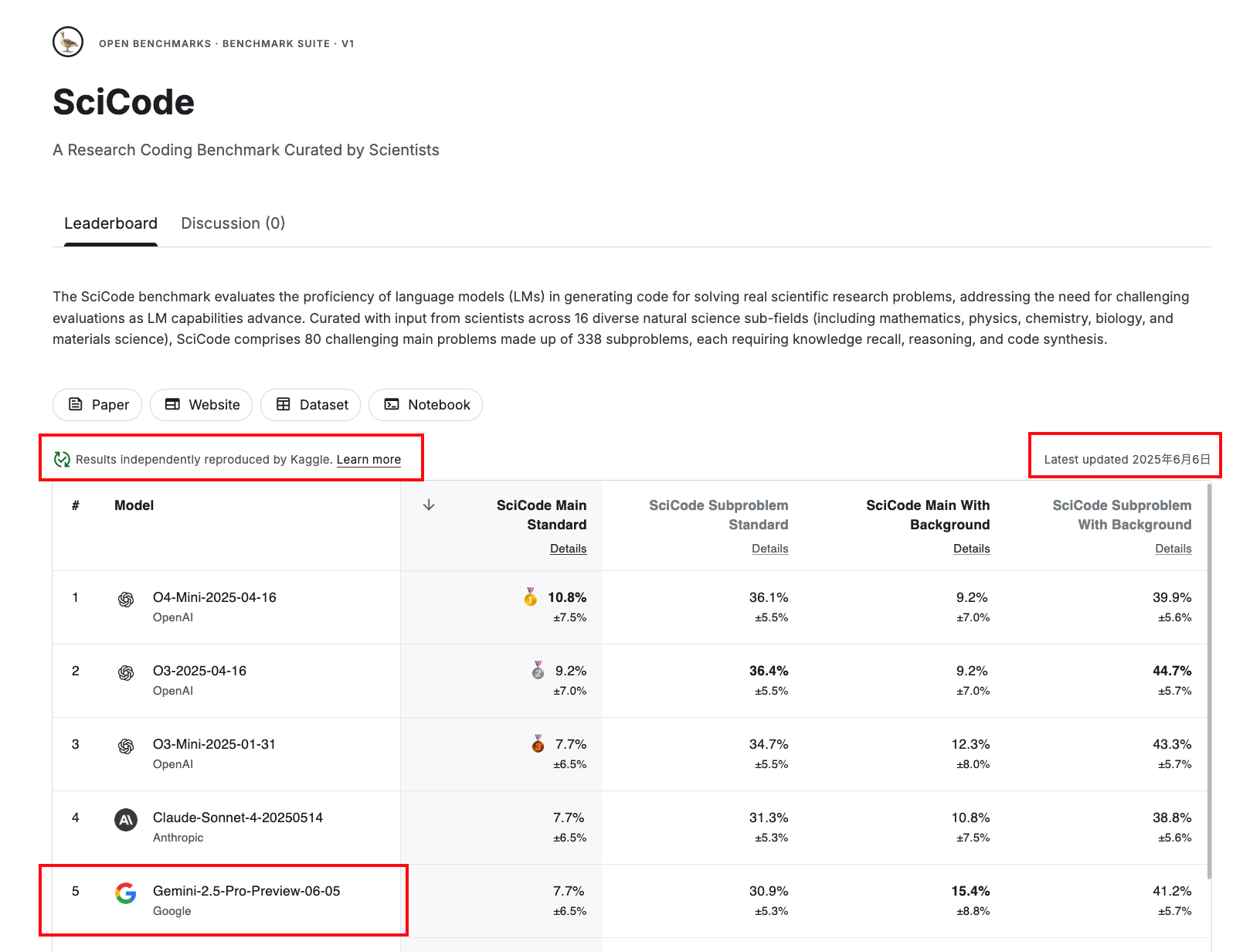
順位表には Benchmark の一式がまとめられ、モデルの名前とスコアがランク付けされています。Kaggle によって独立して再現性を確認したオンラインベンチマークとなっている点が明示されており、この評価のためのコードも Kaggle Notebook として公開されリンクされています。
新しいモデルが出現すると程なくして順位表に追加されていくようです。6月18日現在では、Gemini 2.5 Pro Preview 0605 が 6 位にランクインし、6月6日に順位表が更新されたことがわかります。最近ではオープンウェイトモデルとして MiniMax が登場して話題になっていますが、こちらも登場するのでしょうか。
Benchmark Suite には、内訳となる個々の Benchmark が紐づいています。
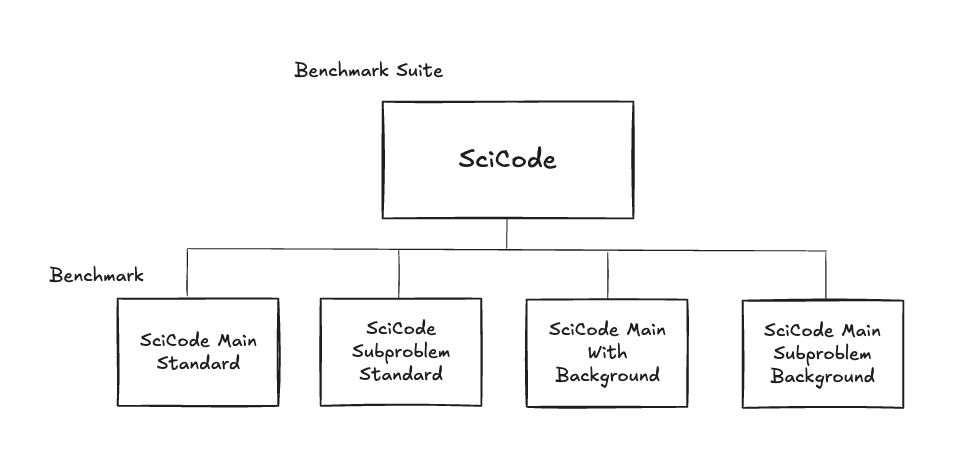
以下は SciCode の Benchmark の一つである “SciCode Main Standard” の例です。
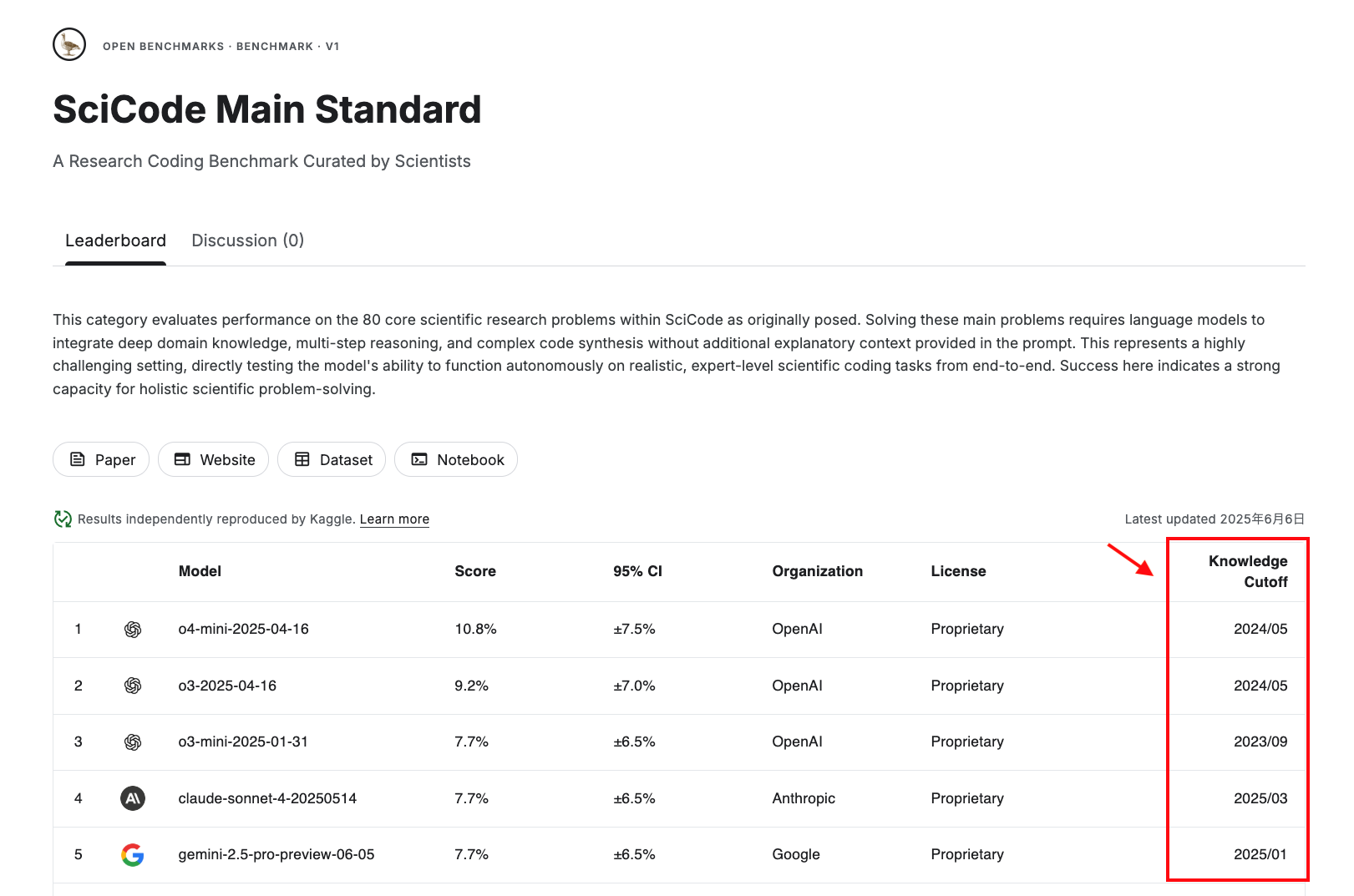
Benchmark ではランク付けされているモデルのメタ情報として “Knowledge Cutoff” (知識が更新された最後の時点) 情報もあわせて併記されています。これは新しい情報がベンチマークにおいて重要な役割を果たしているのか、汚染の可能性が考えられるか、を見る上で参考になりそうです。
重視している3つの原則
Kaggle が何を重視しているのかについては Kaggle Benchmark の公式ドキュメントに詳しく書かれています。 以下は Kaggle Benchmark が遵守する原則として記述されていることです。
-
堅牢性 (robustness)。簡単にハッキングされたり、飽和したり、漏洩したりできない。
-
再現性と透明性。評価を信頼できるようにするために、再現性と透明性を重視する。
-
Kaggleはベンチマークを開発しない。Kaggle の役割は、結果を独自に再現して公開すること、新しいモデルを新しいベンチマークで継続的に評価するためのプラットフォームを提供すること、そしてコミュニティの関与とストレステストの促進。
この堅牢性については Kaggle がコンペティションを通じて蓄積してきた経験が活かされています。例えば FACTS Grounding のベンチマーク では非公開の private held out を用いて評価しています。これにより意図せず正解を学習してしまう汚染(コンタミネーション)を防ぎ、モデルの能力を正確に評価する手段を提供します。
(以下、FACTS Grouding の説明をよーく見ると private held out だけじゃなく public examples も両方使うと書かれている。これは事例数を増やした正確な評価と汚染対策の両立を目指しての設計なのでしょう)

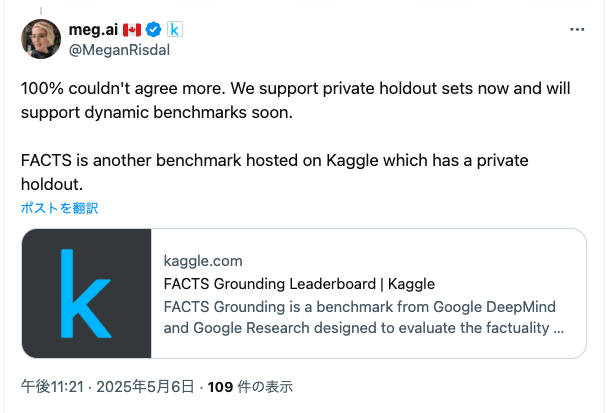
Kaggle Benchmark では SciCode のように public なデータセットを用いたベンチマークでも、FACT Grounding のように private held out を用いたベンチマークも両方サポートしているようです。また Dynamic Benchmark もサポートする予定であることが Kaggle の Megan 氏のツイートで言及されています。
Dynamic Benchmark というのは、時間の経過とともに自然に更新されるソースからテストセットを頻繁に更新するベンチマークのことです。例えば LiveBench というベンチマークは、新しく公開されたニュース記事やarXiv上の論文などから毎週テストセットの質問を更新しています。非常に新しいデータのみでモデルをテストすることにより、そのデータがモデルのトレーニングに含まれるリスクを軽減できます。最新で追加されたテストデータを公開しないことで、常にかなりの割合のテスト事例を非公開に保つことができます。
どのような価値を提供するのか?
SWE-Code, HumanEval, ARC-AGI, LMArena など既存のベンチマークが順位表を持つながで、なぜ Kaggle Benchmark が必要なのか?という疑問があるかもしれません。 これについては、ベンチマーク作者、モデル開発者、業界それぞれに対して以下の価値を提供できるとしています:
-
ベンチマーク作成者:評価を実行し、ベンチマークを長期にわたって維持するための特注のインフラストラクチャを構築する負担が無くなる。例えば、新しいモデルがリリースされるたびに追加する、コンピューティングコストを負担するなど。
-
モデル開発者:厳密さと透明性の基準が高いプラットフォームでモデルのパフォーマンスを議論できる。
-
AI/ML業界:モデルやAIシステムを評価するベンチマークの信頼性、透明性、再現性の基準を高めることで、業界における有用なAI/MLの導入を加速させる。
特にベンチマーク作成者にとってのメリットが大きいと感じます。最近の Kaggle は生成AIモデルの評価の場としての役割にすごい力を入れていて、種類は多くありませんが、主要なモデルのアップデートに対していち早くモデルを更新したり評価をアップデートしています。
評価に用いる API は無料ではないので、Kaggle Benchmark が野放図に増えていくと出費が大変なことになりそうです。現在はユーザーが自由に Benchmark を作成することができず、メールにて問い合わせることで Benchmark をホストするかどうかを判断しているようです。個人的な感想として、ALE-Bench のような興味のあるベンチマークが Kaggle Benchmark に登場してくれたら楽しいだろうなと期待しています(チラチラ)。
生成AIモデル評価のためのゴールドスタンダードとして
Benchmark に関連して、現代の生成AI(GenAI)モデルの評価の課題を指摘し、AIコンペティションをそのための「ゴールドスタンダード」として活用すべきであるというポジションペーパーが ICML’25 にて採択されています。ICML では 2024 からポジションペーパーという論文投稿枠を設けており、この枠での採択論文となります。
AIコンペティションの分野では、コンペティション環境内で不正行為を行う悪意のある参加者(チート行為)に対抗する目的で、リークと戦うための「効果的な対策と実践」が開発されてきました。それはもう数え上げればキリがないほどたくさんの事例の積み重ねがあります。生成AIモデルの評価方法を根本的に改善するために。より具体的には、リークと汚染の回避、および評価の堅牢性向上のために、以下のような方法が役に立つとしています。
隠されたテストデータの保護
Kaggleのようなコンペティションプラットフォームは、参加者がモデルをインターネットアクセスなしの隔離された安全なバックエンドで実行させることで、隠されたテストデータが漏洩しないことを保証できます。膨大な計算資源を使ってこれを実現している点は Kaggle の特異な点とも言えます。ここ数年の Kaggle コードコンペティションのほとんどすべてはこの形式です。これにより、参加者はテストデータに直接アクセスできず、モデルがテストデータを意図せず学習する(汚染される)ことを防ぎます。
リークプルーフ (Leak-Proof) な構造
上述の実行環境の仕組みに加えて、コンペティションはリークを非常に効果的に軽減する独自の構造をもたせることができます。具体的には、以下の3例が挙げられます:
-
将来の正解(Prospective Ground Truth):テストセットのラベルが競争のアクティブなトレーニング段階で完全に未知である戦略です。例えば、CAFA 5 Protein Function Predictionでは、テストセットのタンパク質の機能アノテーションは、コンペティションのアクティブなトレーニング段階でまだ決定されていませんでした。
-
新規タスク生成(Novel Task Generation):テストデータがトレーニングデータとは全く異なる新しいタスクを生成することで、モデルに真の汎化能力を要求します。AI Mathematical Olympiad (AIMO) では、国際的な数学者チームによってコンペティション専用に新しい数学問題が作成されました。
-
提出期限後データ収集(Post-Deadline Data Collection):提出期限後に完全に新しく生成されたデータでモデルを評価します。Konwinski Prize や WSDM Cup Multilingual Chatbot Arena が具体例として挙げられます。これらのコンペティションでは、提出期限後に新しいデータセットが公開され、参加者はそのデータセットに対してモデルを評価することが求められます。
等しく重要なこととして、コンペティションは参加者がテストデータにアクセスできないようにするための構造を持っているということです。
以下は Konwinski Prize のコンペティション構造を示す NeurIPS での発表スライドの一部です。agent submissions を quoter Q で締め切った後に quoter Q+1 (未来) のテスト事例で評価することを説明しています。
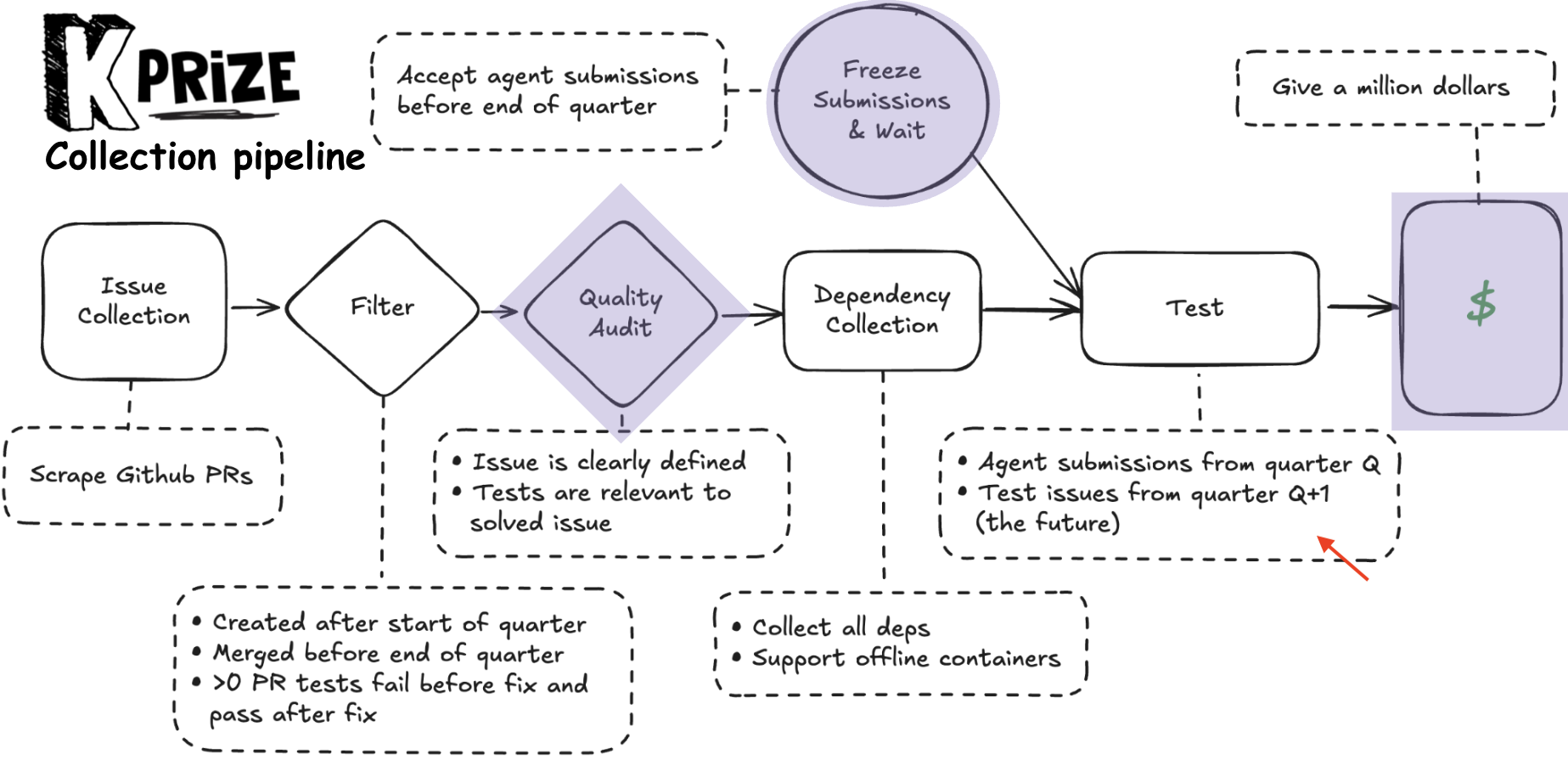
このほか論文では、たくさんの参加者からなる並列評価による効率と信頼性の向上、透明性の確保、コミュニティの関与とストレステストの促進など、AIコンペティションが提供する他の利点にも言及されています。
今後の期待と所感
Kaggle はコンペティションのプラットフォームとして成長してきた経緯があり、コンペティションばかりが注目されがちです。実際私もコンペティションの熱狂的なファンでもあります。そういったコンペティションの仕組みが生成AIの評価において活用され、またモデルのベンチマークの場として Kaggle が進化しようとしている一端が見える面白い取り組みであったので紹介しました。
AIコンペティションの結果そのものを学術的に活用することは、実のところ難しい面もあります。とはいえ、参考値としての参照されることはこれまでもありました。これらの取り組みの先に、今後さらに活用される可能性があると感じています。

