Image Matching Challenge 2023 の優勝チームの実験結果のデモが非常にうまくいっていた。再現実装をしたくなったので彼らのチームが出した論文を読んだ。
Detector-Free Structure from Motion
We propose a new structure-from-motion framework to recover accurate camera poses and point clouds from unordered images. Traditional SfM systems typically rely on the successful detection of repeatable keypoints across multiple views as the first step, which is difficult for texture-poor scenes, and poor keypoint detection may break down the whole SfM system. We propose a new detector-free SfM framework to draw benefits from the recent success of detector-free matchers to avoid the early determination of keypoints, while solving the multi-view inconsistency issue of detector-free matchers. Specifically, our framework first reconstructs a coarse SfM model from quantized detector-free matches. Then, it refines the model by a novel iterative refinement pipeline, which iterates between an attention-based multi-view matching module to refine feature tracks and a geometry refinement module to improve the reconstruction accuracy. Experiments demonstrate that the proposed framework outperforms existing detector-based SfM systems on common benchmark datasets. We also collect a texture-poor SfM dataset to demonstrate the capability of our framework to reconstruct texture-poor scenes. Based on this framework, we take $\textit{first place}$ in Image Matching Challenge 2023.
以下はGithubリポジトリにアップロードされているデモ動画。テクスチャの乏しいシーンでも正確なカメラ位置を推定できるところが強い。
やっていること
タスクは同一シーンを撮影した順不同の画像集合から画像のカメラ姿勢 , (3x3 rotation matrix, 3x1 translation vector) を復元する。テクスチャの乏しい領域ではマッチングによって複数のビューにまたがる再現可能なキーポイントを頑健に検出することは困難。そのため detector-based method ではなく LoFTR などの detector-free な feature extractor の特性を活かした SfM の手法を提案し、これによってテクスチャ情報の乏しいシーンにおいても高精度なカメラ姿勢推定が可能とした。
以下が全体像。Coarse Model を得るための Mapping は COLMAP の Incremental Mapper を利用している。Coarse Match Quantization と Feature Track Refinement が新規性のある差分となる。
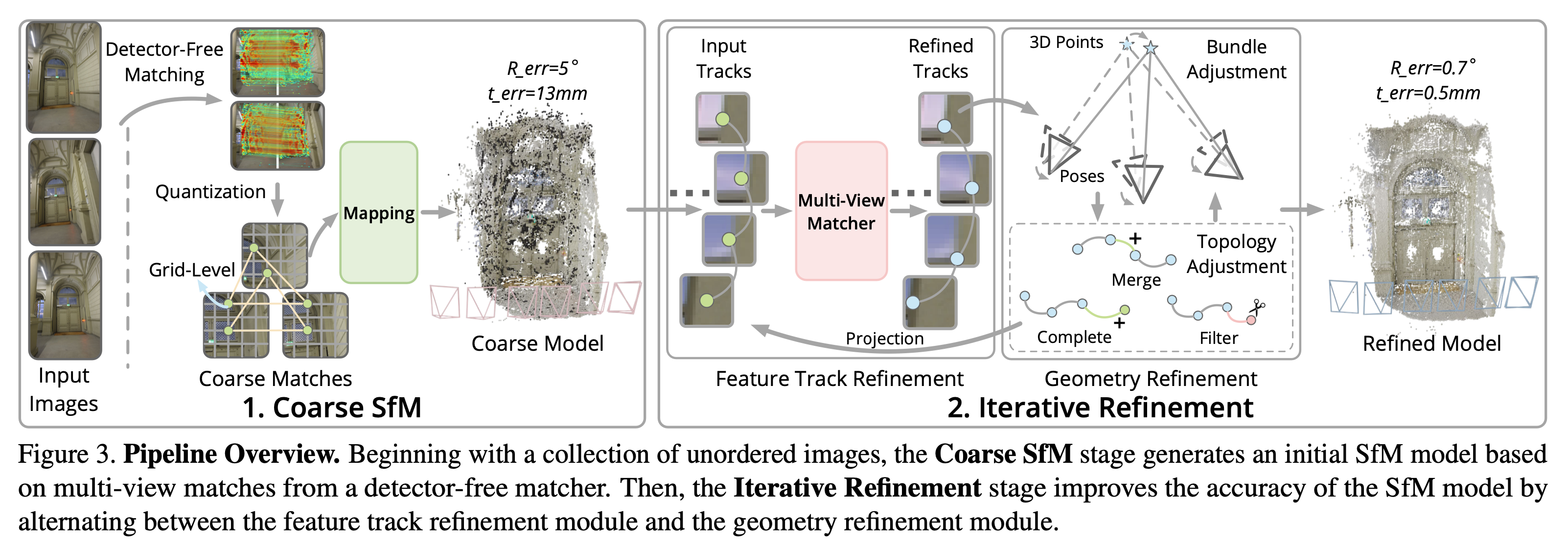
Coarse Match Quantization
提案手法のアイディアは coarse SfM での精度を犠牲にすることでマッチングの一貫性に努めること。具体的には 2D 座標位置 を に丸め込みしたグリッド上に再配置する。 はグリッドの cell size となるハイパーパラメータ。
この量子化によって近い複数の subpixel matches が一つの grid node にマージされるため、一貫性が向上する。この一貫性の向上が複数ビューで pairwise matching を行う際に特徴トラックが断片化されてしまうことを防ぐ。なぜ重要かというと特徴トラックを入力として iterative に改善していくため、これが断片化されていると改善がうまくいかない。
Ablation Study では Quantization ratio の変更による比較が 4.5 で紹介されている。他の変更と比較すると影響は軽微であるように見える。Quantization ratio を小さくすることで高精度になる一方で計算時間が増える傾向にある。
Feature Track Refinement
ある 3D scene point に対応する multi-view images の 2D keypoint locations 集合として、特徴トラック を定義する。 .
この特徴トラックを入力とした Multi-view feature transformer モデルを導入して、局所特徴の相関を最大化することで全ビューの keypoint (座標)を局所的に調整する。すべてのビューのペアを網羅的に相関させることは計算上困難なので、reference view を選択して、reference view の keypoint の特徴と他の view (query view) の keypoint の特徴を相関させる。
具体的には keypoint の周りの サイズの局所特徴マップの相関から のヒートマップを query view ごとに得る。これは keypoint location の分布として見ることができる。この heatmap を使って query view の keypoint location を補正する。
もっと詳しく
上述は query view の keypoint location の補正についての説明。reference view の keypoint は固定された状態の話であった。reference view の keypoint についても複数候補を作成して推定することを考える。
reference view の元々の keypoint の周辺 の grid 上から座標をサンプリングして、複数の特徴トラックの候補 (candidate tracks) を作成する。下図では として周辺 8 座標 (reference location) をサンプリングしている。
それぞれの reference location に対して、上述したように reference location の特徴と query view の特徴パッチと相関を計算して、query view において予想される keypoint locations とその分散を示す heatmap を取得し、特徴トラックを得る。これが candidate track となる。分散が最も小さい candidate track を選択して、refined track として扱う。
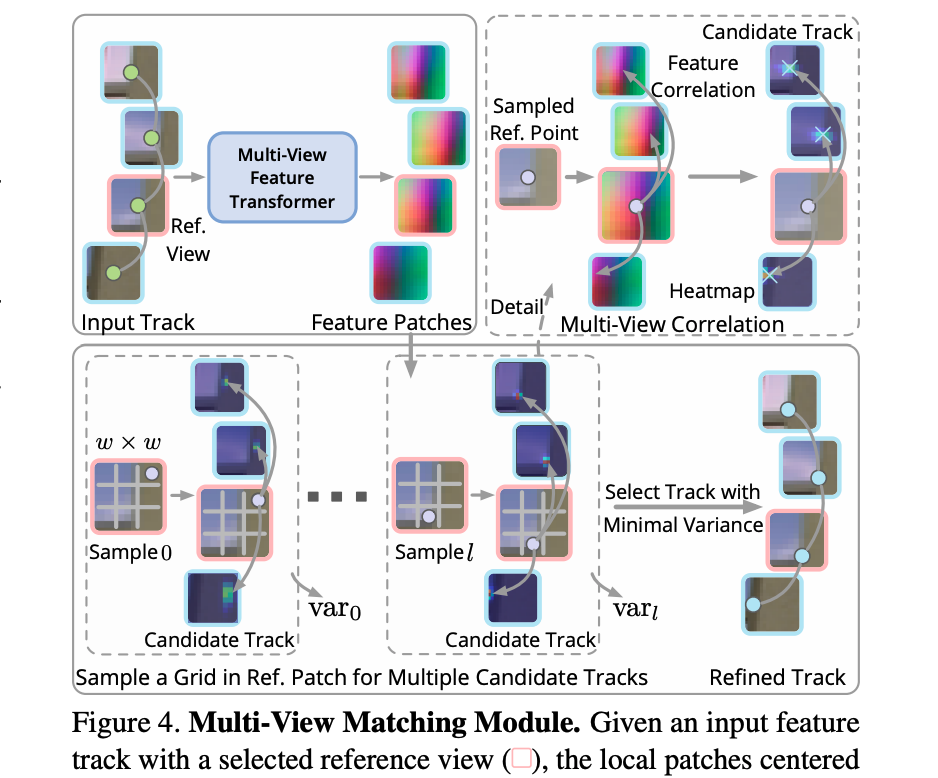
整理をすると、
- 特徴トラックから reference view を選択する
- reference view の keypoint の周辺 の grid から reference location をサンプリングして、複数の特徴トラック候補を作成する
- 特徴トラック候補における query view の keypoint location を決定するために、 の image patches から multi-view feature transformer により feature patches を抽出して、その reference との相関によって heatmap を作る
- heatmap から query view の keypoint location を決定する
- 分散最小の特徴トラック候補を選択して refined track とする
Multi-view Feature Transformer
特徴トラックの keypoint を中心とした の image patches を CNN backbone に入力して feature patches を得る。 はチャンネル数。この を とするように flatten して を得る。
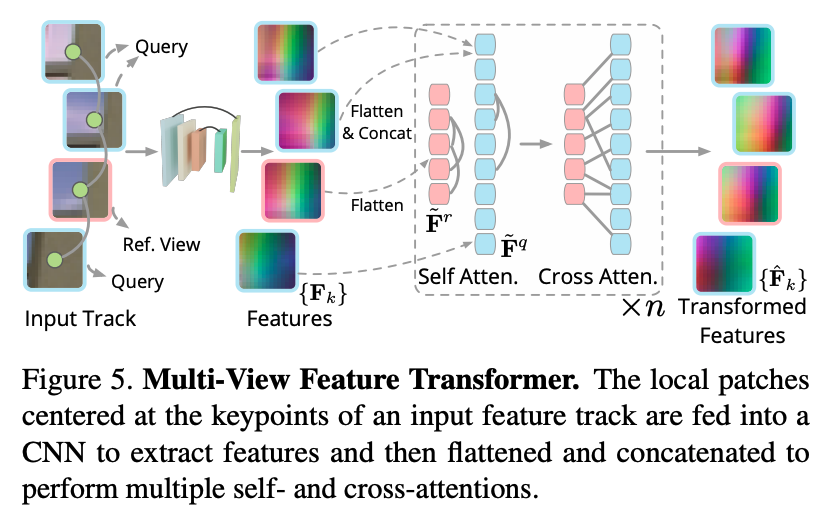
これを最初の dimension に沿って連結して単一の特徴 とする。これに reference feature と self-attention, cross-attention を 回適用することで multi-view feature を得る。
Training
Multi-view Feature Transformer は MegaDepth データセットを使って洗練された特徴トラックと ground truth のトラックの間のキーポイント位置の平均 L2 loss を最小化することで学習する。
訓練データセットは各シーンから最大6枚の画像が含まれている image bag をサンプリングすることで構築する。image bag は co-visibility 領域がある画像集合で、与えられた SfM model から抽出する。ground truth 特徴トラックは bag からランダムに reference image を選択して grid points を他の query view に射影して得る。
Geometry Refinement
Feature Track Refinement によって洗練された特徴トラック に基づき、以下を洗練する。
- 姿勢
- intrinsics
- 3D points
- 特徴トラックのトポロジー
特徴トラックのトポロジーは連結した 2D keypoint の集合のグラフ構造を意味する。BA で , , を調整して TA で特徴トラックのトポロジーを調整する。
Bundle Adjustment (BA)
提案手法では洗練された特徴トラックに基づいて姿勢と点群を最適化するために効率的にBAできる。形式的には intrinsic パラメータ , 姿勢 , 3D points を reprojection error の最小化で最適化:
Topology Adjustment (TA)
BA を実行したあと、refine されたモデルに基づいて Topology Adjustment (TA) を実行する。これは Complete, Merge, Filter の 3 つの操作を行う。この操作は基本的に COLMAP, VisualSFM と同様に行う。
- Complete: Refinement 前の特徴トラックに登録されていなかった 2D keypoint を特徴トラックに追加する
- Merge: Reprojection criteria を満たす特徴トラックをマージする
- Filter: Outlier filtering. refinement 後に maximum reprojection threshold を満たさない point を削除する
上述の BA と TA を交互に複数回繰り返すことで洗練された poses と point clouds を得る。この結果を元に次の iteration で multi-view matching を行う。
所感
全体について。複雑なパイプラインであるが keypoint を増やすことで精緻化の改善幅を大きくすることができる優れたアプローチであると思う。
Corase Match Quantization について。Image Matching Challenge 2023 では NMS によって Merge していると説明されているが、論文ではもっと軽量な Quantization によって処理されている。この Quantization の重要さが理解しきれていない。特徴トラックが断片化されてしまうので後段の refinement ができなくなるという問題はありそうだが、十分な数の keypoint があるので最終的な結果への影響は軽微ではないかという疑問が残る。Coarse Match Quantization を使わなかった場合の結果が気になる。

