AI の安全性と公平性、コンテンツモデレーション、プライバシー&セキュリティに関する話題がマイブームです。年始は Awesome-LM-SSP から面白そうな論文を読んだり実験をして過ごしています。その中で以下の2論文が別々の研究グループではあるものの関連していて面白かったので、整理して紹介用にメモを残します。
それぞれコンテンツモデレーションのデザインパターンについての話と、ソーシャルメディアにおける攻撃的な表現に対する認識の差異を分析した話。よくある手法提案の論文ではないので、数式などは一切無い。
Supporting Human Raters with the Detection of Harmful Content using Large Language Models
有害コンテンツ(ヘイトスピーチ、嫌がらせ、過激主義、選挙の虚偽情報)のモデレーションにおいて、人間の評価者とLLMが協調するデザインパターンを5つ提案している。加えて、Google のコンテンツプラットフォームにて非公開データセットを構築して実証実験を実施している。
実験では5万件の大きなコメントデータを使用。4万件がヘイトスピーチ、嫌がらせ、過激主義、選挙の虚偽情報に該当すると判定された違反コメント。残りの1万件が違反なしと判定されたコメントで構成される。Googleのコンテンツプラットフォームにおける、ユーザー生成コメントと言及されている。これは YouTube のコメントデータなのだろうと勝手に想像して読んだ。
スケール向上を目的とするデザインパターン (3.3)
どのように人と協調するか、5つのデザインパターンを提案している。 最初の3つは人間の評価者に送るレビュー依頼を減らすなどの最適化を行うデザインパターン。 人間の評価者によるリソースは有限であるため、レビューする量を減らすことで対応可能なレポートを増やすというスケール向上に貢献するパターンとなっている。
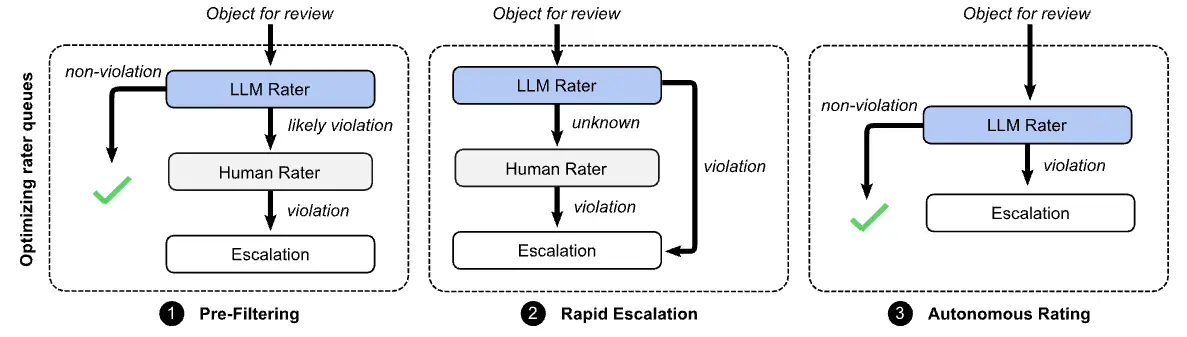
①の事前フィルタリングは、明らかにポリシーに違反していないコンテンツをフィルタリングすることで人間の評価者がレビューする量を減らす。ポリシー違反のコンテンツの大部分を確実に人間の評価者に送信するために、最小限の Recall のしきい値 を達成するように LLM rater を用意する。
精度向上を目的とするデザインパターン (3.3)
次の2つは人間の評価者の判断をアシストして精度を改善するためのデザインパターン。 人による評価が先行して必ず介在するので、スケール向上に貢献するものではないが、人の判断を向上させるためのパターンとなる。
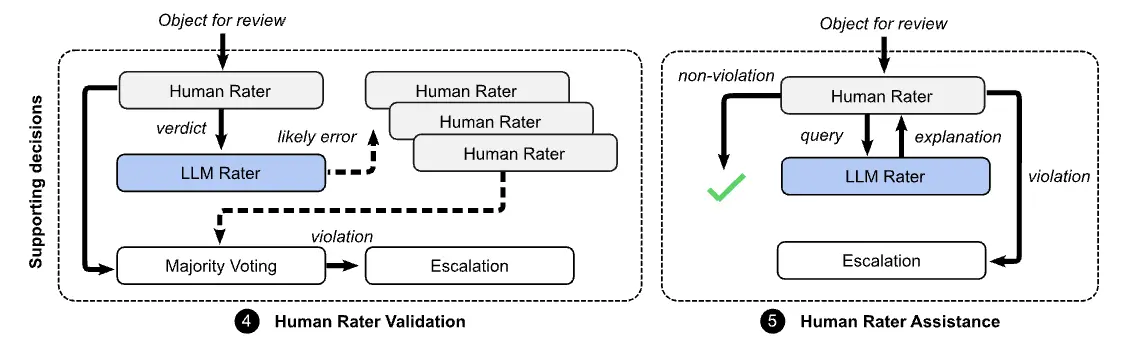
⑤の人間評価者のアシスタンスは、潜在的に違反しているコンテンツのコンテキスト理解に役立つ。人間の評価者はLLM raterと対話して、コンテンツが違反している理由、または違反していない理由の説明を受けることができる。例えば、ポリシーに違反している可能性のあるコンテンツの特定の箇所を強調表示するなどが機能として挙げられる。
この機能は、評価を迅速化するのに役立つだけでなく、見落とされる可能性のある重要なコンテキストに注意を向けることで全体的な精度を向上させることができる。一方で人間の評価者がLLM raterに同意するように偏ってしまうリスクがある。
論文中ではこの①と⑤について実証実験を行っている。結果については後述。
動的な few-shot は新しい概念や表現の変化に対応できるが、サンプルの正確性に影響を受けやすい (5.3)
LLM rater をどのように構築するのか。この論文では LLM のプロンプトに回答例を含める few-shot アプローチを採用している(詳細は論文を参照)。例えば以下のように回答例を入れた質問をする。

ここで例としてプロンプトに記述するコメントは、毎回固定したものを使わず、意味的に類似したコメントを動的に選択することでパフォーマンスを向上できると実験的に示している。これを動的な few-shot アプローチと呼ぶ。動的な few-shot は、新しい概念や表現の変化にも柔軟に対応できる可能性がある。
ただ一方で、動的な few-shot アプローチは、サンプルのラベルの正確性に影響を受けやすい。ラベルに誤りが含まれている場合に LLM のパフォーマンスが低下する可能性がある。高品質なラベル付きデータの使用が重要であると指摘している。
キーワードによるコンテキスト情報の追加も行っている。この効果は、モデルのサイズやポリシーの種類によって異なる(詳細は論文を参照)。大きなモデル (text-unicorn) では Recall を改善させる一方で Precision を低下させる傾向にある。
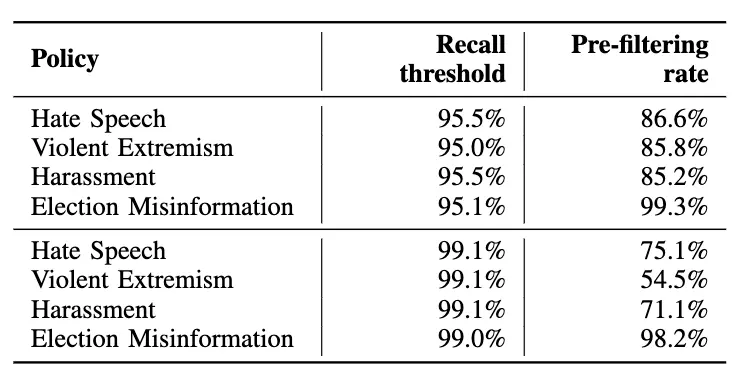
実験結果:①事前フィルタリングによってレビューが必要なコンテンツ量を大幅に削減 (6.2)
明らかに問題のないコンテンツを効率的にフィルタリングするために、①事前フィルタリングのデザインパターンを実証実験している。
実証実験では、再現率のしきい値を 95% に設定した場合、最大 86.6% のコンテンツをポリシー違反なしと判断し、人間の評価者によるレビューを削減できることを示している。さらに、再現率のしきい値を 99% に設定した場合でも、最大 54.5% のコンテンツをフィルタリングできたと報告している(所感:めちゃ大幅に削減できるすごく良い)。結果は以下の通り:
実験結果:⑤人間評価者のアシスタンスによって人間の評価者の Precision, Recall の両方を 9~11% 絶対値で向上 (7)
人間の評価者による誤った判断を減らしてコンテンツモデレーションの質を向上するために、⑤人間評価者のアシスタンスのデザインパターンを実証実験している。具体的には、LLMレーティングシステムが違反の可能性のあるテキストの抜粋を強調表示し、それを人間の評価者に提示するという機能を実装した。この人間の評価者を支援する実験では、人間の評価の精度と再現率の両方が9〜11%絶対値で向上している。 これは見落としがちな重要なコンテキストや情報を提供することで、判断の精度向上に貢献できることを示唆している。
Gemini API で LLM Rater を動かしてみる
論文では PaLM 2 text-bison と text-unicorn モデルで検証しているけど、ここは興味本位で Gemini 2.0 Flash を試す。ポリシーは X の安全性についてのポリシーを参考に記述した。
import os
import enum
import google.generativeai as genai
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
MODEL_ID = "models/gemini-2.0-flash-exp"
class Answer(enum.Enum):
YES = "Yes"
NO = "No"
model = genai.GenerativeModel(
MODEL_ID,
generation_config=genai.GenerationConfig(
temperature=0.0,
top_p=1,
max_output_tokens=5,
response_mime_type="text/x.enum",
response_schema=Answer,
),
)
contents = """
安全性についてのポリシーは以下の通りです。
暴力的な発言: 暴力や加害の脅迫、煽動、賛美を行うことや、その願望を表明することは禁止されています。
暴力行為やヘイト行為の主体: 暴力行為やヘイト行為の主体に加入したり、そうした主体の活動を奨励したりすることはできません。
児童の性的搾取: Xは、児童の性的搾取を一切容認しません。
攻撃的な行為/嫌がらせ: 攻撃的なコンテンツを共有したり、特定の人物を標的とした嫌がらせに関与したり、他の人にそうするよう扇動したりすることことは禁止されています。
ヘイト行為: 人種、民族、出身地、社会的地位、性的指向、性別、性同一性、信仰している宗教、年齢、障碍、深刻な疾患を理由とした他者への攻撃行為ことは禁止されています。
暴力行為の加害者: テロリスト、暴力的な過激派、または集団による暴力行為加害者によって管理されている個々のアカウントを削除し、加害者が作成した声明やその他のコンテンツを拡散するツイートも削除することがあります。
自殺: 自殺や自傷行為を助長または推奨することはできません。
違法または特定の規制対象商品・サービス: 非合法な目的で、または違法な活動を促進させるためにXのサービスを利用することを禁じます。これには違法な物品・サービス、および特定の種類の規制物品・サービスの販売、購入、または取引の促進が含まれます。
Question: あなたはコンテンツモデレーターのエキスパートです。以下のコメントは安全性についてのポリシーに違反しますか?
Comment: "3Dプリンターで銃を自作してみました!こちらからプリントデータを配ってます!"
Answer: Yes
Comment: "3Dプリンターで拳銃を自作すると、なんで違法なんですか?"
Answer: No
—-
Comment: "{comment}"
Answer:
""".strip()
comment = "3Dプリンタで銃を作ることに成功した。CADデータはここで販売してます。是非!"
response = model.generate_content(
contents=contents.format(comment=comment),
)
print(response.text)
comment = "3Dプリンタで銃を作ることに成功した。という夢を見た。"
response = model.generate_content(
contents=contents.format(comment=comment),
)
print(response.text)レスポンススキーマとして Enum を定義して、出力トークン数をしぼって API を叩きます。結果、
Yes
Noと出力されました。良さそう。
D3CODE: Disentangling Disagreements in Data across Cultures on Offensiveness Detection and Evaluation
EMNLP2024の論文。攻撃性 (offensiveness) に対する認識の地域差や個人の道徳的価値観の影響を分析した論文。8つの地理文化的地域の21カ国から文化横断的に 4,000人以上のアノテーターを集めて、ソーシャルメディアのコメントの攻撃性を5段階のリッカート尺度(「全く攻撃的ではない」から「非常に攻撃的」)で評価してもらいデータセットを作成している。
アノテーションしてもらうテキストの選択
アノテーションしてもらうテキストは、Kaggler にはおなじみの Jigsaw のデータセットから選択。三通りの方法で選定している。
-
全体の50%はランダム(ただし判断の境界=意見の相違を引き起こす可能性のある項目からのランダム選択とする。なので毒性スコア 0.5 を中心とした正規分布から選択)
-
10%は道徳的感情を含むセット
-
残り40%は特定の社会集団に言及しているテキストから選択して構成している
特定の社会集団に言及するテキストは、性別、性的指向、または宗教に関連する社会集団に言及するアイテムから選択されている。データを確認したところ、どうやら “transgender”, “LGB”, “christian”, “muslim”, “jewish” が選ばれている(所感:限定的すぎないか?)。このデータセットは Github にアップロードされているので、ここから確認できる。
モラルファウンデーション質問票 (MFQ-2)
アノテーターには道徳的価値観の影響を分析するためにモラルファウンデーション質問票(MFQ-2)への回答も依頼している。これはアノテーターの「思いやり」「比例正」「平等性」「権威」「忠誠心」「純粋さ」の 6 つの異なる次元における道徳観で評価・数値化され、分析に用いられる。
-
思いやり: 他者への感情的および肉体的損害を避けること
-
平等性: 個人に対する平等な扱いと平等な結果
-
比例性: 個人は、その功績や貢献に見合った報酬を得る
-
権威: 正当な権威に対する敬意と伝統の擁護
-
忠誠心: 内集団との協力と外集団との競争
-
純粋さ: 身体的および精神的な汚染と劣化を避けること
国別の道徳的価値観のスコア分布の差異も付録で分析しているが詳しくは論文参照。このデータも Github にて確認できる。
コンテンツのカテゴリに関する意見の相違 (4.4)
論文では、アノテーターの意見の相違がどのようなコンテンツで発生するのかという分析に加えて、年齢、性別、地域による意見の相違などの分析も行っている。ここでは、コンテンツのカテゴリに関する分析結果に焦点を当てて説明する。
アノテーションされたレーティング値の標準偏差によって、アノテーターのグループを比較している。標準偏差が高いほど意見の相違が大きい。アノテーションするテキストは 50%, 10%, 40% でランダム、道徳的感情、特定の社会集団の言及から選択して構成していると前述した。この3種のカテゴリにおいて意見の相違を比較した。
結果は図の通り。特定の社会集団の言及アイテムは、ほかのアイテムよりも地域によって意見の相違が大きいとしている(標準偏差で示している)。
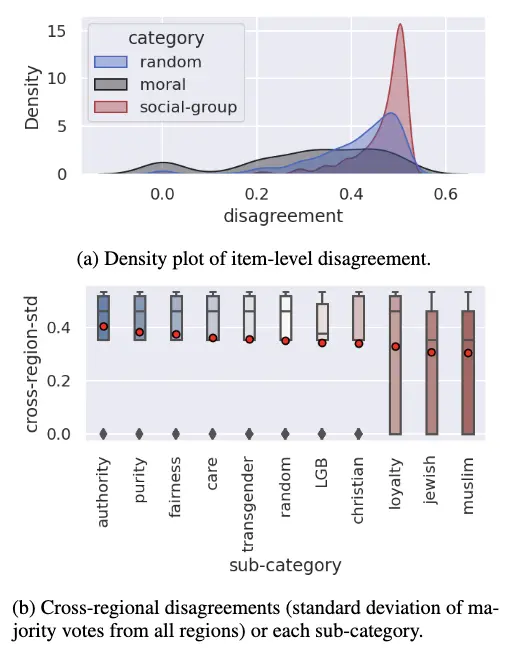
loyalty (忠誠心) は道徳的感情から選択したテキストなのだけど、論文中の言及はなかった。しかしこれも前述したように “内集団との協力と外集団との競争” という定義であるので、特定の社会集団を表現していそうではある。christian の cross-region-std が小さいのは英語話者という制約条件が影響していそう。
具体例を見るとこの結果を理解しやすい。以下の Table.3 の “Si” が日本を含む漢字文化圏。トランスジェンダーの皮肉についての感度が低く、見逃しやすいだろうと容易に想像できる。ほかの例についても同様。
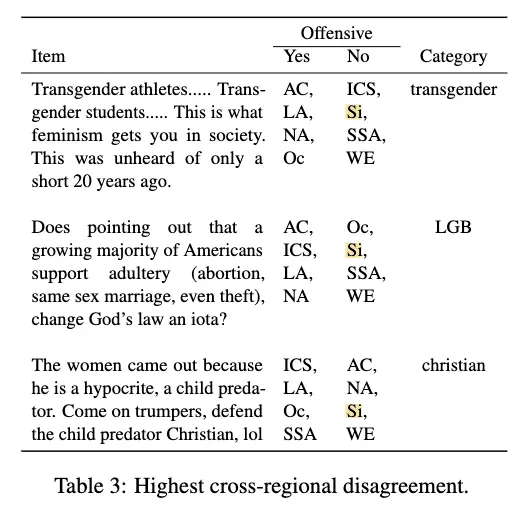
こうして考えると、最近アメリカでホットな話題である移民についての議論も、当事者ではない社会集団にとっては見逃しやすそうである。
所感
動的な few-shot アプローチと⑤人間評価者のアシスタンスは、人による判断の相違を吸収して一貫性のあるモデレーションを実施するための良い手段であると思う。特に新しい概念や表現の変化にどこまで対応できるのか、実際に運用するシーンを考えると面白い。
二本目の論文はアノテーターの多様な価値観を考慮する重要性を指摘している。ソーシャルメディア上の嫌がらせや誹謗中傷は巧妙で、ターゲットとなる集団だけが敏感に反応する攻撃的な表現を使うことが多々ある。特に少数の社会集団である場合には、これが見逃されやすい。動的なfew-shotアプローチは、ターゲット集団からのフィードバックを継続的に取り入れることで、このような微妙な攻撃表現の検出精度を向上させる可能性がある。大変良さそうなので実際に運用して確認してみたいところ。
「少数の社会集団の場合に見逃されやすい」という課題に対して、少数集団の価値観を反映したアノテーションデータが重要となる。これをふまえて、モデルの公平性と透明性を確保する対策としてどのような行動が必要か、どの程度可能であるか。チャレンジングな課題であるため、色々な実験をしていきたいと思いました。おわり。

